United Kingdom
StephanLewandowsky
2020-03-29
Last updated: 2021-02-15
Checks: 7 0
Knit directory: UKsocialLicence/
This reproducible R Markdown analysis was created with workflowr (version 1.6.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200329) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 6da5a32. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/4 OSF Spain+social+licencing+COVID+Wave+1.csv
Ignored: data/4 OSF U.S.+social+licencing+COVID+Wave+1.csv
Ignored: data/4 OSF UK+social+licencing+Wave+2.csv
Ignored: data/4 OSF US varCovid.xlsx
Ignored: data/4 OSF varSpainCovid.xlsx
Ignored: data/4 OSF varUKCovidW2.xlsx
Ignored: data/Lucid SES info Spain 1.xlsx
Ignored: data/Spain+social+licencing+COVID+Wave+1.csv
Ignored: data/U.S.+social+licencing+COVID+Wave+1.csv
Ignored: data/UK early data covid 1st 500/
Ignored: data/UK+social+licencing+COVID+Wave+2.csv
Ignored: data/dupsUK.dat
Ignored: data/dupsUK2.dat
Ignored: data/dupsUS.dat
Ignored: data/varSpainCovid.xlsx
Ignored: data/varUKCovid.xlsx
Ignored: data/varUKCovidW2.xlsx
Ignored: data/varUSCovid.xlsx
Ignored: data/varnamediffs.csv
Untracked files:
Untracked: analysis/Paul's code/
Untracked: covhisto.pdf
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/UKcov1.Rmd) and HTML (docs/UKcov1.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 5bd9045 | StephanLewandowsky | 2021-02-05 | Build site. |
| html | bb03a95 | StephanLewandowsky | 2020-11-16 | Build site. |
| html | 7a92223 | StephanLewandowsky | 2020-11-15 | Build site. |
| html | fd1e250 | StephanLewandowsky | 2020-09-30 | Build site. |
| html | d6c4ad2 | StephanLewandowsky | 2020-07-28 | Build site. |
| html | 680986f | StephanLewandowsky | 2020-07-06 | Build site. |
| Rmd | 4f64552 | StephanLewandowsky | 2020-07-06 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 4f64552 | StephanLewandowsky | 2020-07-06 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 75ee0b1 | StephanLewandowsky | 2020-06-12 | Build site. |
| html | 4841846 | StephanLewandowsky | 2020-05-20 | Build site. |
| html | 0937f8f | StephanLewandowsky | 2020-05-11 | Build site. |
| html | 2994975 | StephanLewandowsky | 2020-05-09 | Build site. |
| html | 7b7609a | StephanLewandowsky | 2020-05-07 | Build site. |
| html | a6c93f1 | StephanLewandowsky | 2020-05-06 | Build site. |
| html | 7b6f263 | StephanLewandowsky | 2020-05-05 | Build site. |
| Rmd | bce7b96 | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | bce7b96 | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | bfd84e0 | StephanLewandowsky | 2020-05-05 | Build site. |
| Rmd | 3504379 | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 3504379 | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | c656f8d | StephanLewandowsky | 2020-05-05 | Build site. |
| html | 641e4c5 | StephanLewandowsky | 2020-05-05 | Build site. |
| Rmd | e7cfb3d | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | e7cfb3d | StephanLewandowsky | 2020-05-05 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 8061134 | StephanLewandowsky | 2020-04-27 | Build site. |
| html | 8370270 | StephanLewandowsky | 2020-04-26 | Build site. |
| html | 33b991d | StephanLewandowsky | 2020-04-19 | Build site. |
| html | fdb4ddc | StephanLewandowsky | 2020-04-17 | Build site. |
| html | e4874ce | StephanLewandowsky | 2020-04-17 | Build site. |
| html | a1a91ec | StephanLewandowsky | 2020-04-17 | Build site. |
| Rmd | 41469ac | StephanLewandowsky | 2020-04-17 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 41469ac | StephanLewandowsky | 2020-04-17 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| html | 3149892 | StephanLewandowsky | 2020-04-17 | Build site. |
| html | bf52830 | StephanLewandowsky | 2020-04-17 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, |
| Rmd | 5e04926 | StephanLewandowsky | 2020-04-17 | intermittent update of code before knitting. |
| html | 506032d | StephanLewandowsky | 2020-04-12 | Build site. |
| html | b46a0c8 | StephanLewandowsky | 2020-04-11 | Build site. |
| html | 3f0daff | StephanLewandowsky | 2020-04-10 | Build site. |
| html | 70a0d30 | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | 0e9a4b6 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 0e9a4b6 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 025fc9a | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | ab9c89f | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | ab9c89f | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 4e80cee | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | a7fe1f5 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | a7fe1f5 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | e7556ff | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | 6da27c7 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 6da27c7 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | f763157 | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | 8017e53 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 8017e53 | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | a434047 | StephanLewandowsky | 2020-04-09 | Build site. |
| Rmd | 93bb84d | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 93bb84d | StephanLewandowsky | 2020-04-09 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/USCov.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 77d31f2 | StephanLewandowsky | 2020-04-08 | Build site. |
| Rmd | 0fa4d46 | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | 0fa4d46 | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”, “analysis/socialLicencing.R”), all = TRUE) |
| html | b375418 | StephanLewandowsky | 2020-04-08 | Build site. |
| Rmd | 1e2a3aa | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | 1e2a3aa | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | 8c1b465 | StephanLewandowsky | 2020-04-08 | Build site. |
| html | c74ad1c | StephanLewandowsky | 2020-04-08 | Build site. |
| Rmd | f76ffb9 | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | f76ffb9 | StephanLewandowsky | 2020-04-08 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | 28f45c6 | StephanLewandowsky | 2020-04-07 | Build site. |
| html | 8d01aa6 | StephanLewandowsky | 2020-04-07 | Build site. |
| Rmd | 00e5d9e | StephanLewandowsky | 2020-04-07 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | 00e5d9e | StephanLewandowsky | 2020-04-07 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”), all = TRUE) |
| html | d879a85 | StephanLewandowsky | 2020-04-06 | Build site. |
| html | ad12428 | StephanLewandowsky | 2020-04-03 | Build site. |
| Rmd | 94cc0a6 | StephanLewandowsky | 2020-04-03 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 8207fc0 | StephanLewandowsky | 2020-04-03 | Build site. |
| Rmd | d491cdb | StephanLewandowsky | 2020-04-03 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | fc278e3 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | 0b0a917 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 1445dd1 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | e209428 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | a5f6c98 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | a004e59 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 09041d9 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | 95911d0 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 44f5600 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | 663b29d | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 3d697eb | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | b917b30 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 469a858 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | 0b43c59 | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 7343711 | StephanLewandowsky | 2020-04-02 | Build site. |
| Rmd | 5b6f56a | StephanLewandowsky | 2020-04-02 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 3967729 | StephanLewandowsky | 2020-04-01 | Build site. |
| Rmd | b7b00cc | StephanLewandowsky | 2020-04-01 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 408034b | StephanLewandowsky | 2020-04-01 | Build site. |
| Rmd | 002bbf8 | StephanLewandowsky | 2020-04-01 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 0d96959 | StephanLewandowsky | 2020-04-01 | Build site. |
| Rmd | 895f4e4 | StephanLewandowsky | 2020-04-01 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | f57e299 | StephanLewandowsky | 2020-04-01 | Build site. |
| Rmd | 43a97db | StephanLewandowsky | 2020-04-01 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | d08ab5e | StephanLewandowsky | 2020-04-01 | Build site. |
| Rmd | 013339b | StephanLewandowsky | 2020-04-01 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | e48563a | StephanLewandowsky | 2020-04-01 | Build site. |
| html | 4e74f63 | StephanLewandowsky | 2020-04-01 | Build site. |
| html | 21f7d7b | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 03f1462 | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 81fd7f8 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 4c0d677 | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | c5a83f3 | StephanLewandowsky | 2020-03-31 | Build site. |
| html | c23c1c7 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 6ce8fdd | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 0c157a6 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 09a250b | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 5a0656b | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 7cb806b | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 8f0e389 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | f387a24 | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | ce4568d | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 1b3e18c | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 6b138eb | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 6599a1c | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 1fbe6b1 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | c6be52c | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | e8f5bea | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | edab6d2 | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 7ba2f04 | StephanLewandowsky | 2020-03-31 | Build site. |
| Rmd | 9a33ff8 | StephanLewandowsky | 2020-03-31 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | fabd9a9 | StephanLewandowsky | 2020-03-30 | Build site. |
| Rmd | 237cc37 | StephanLewandowsky | 2020-03-30 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
| html | 9b85df1 | StephanLewandowsky | 2020-03-29 | Build site. |
| Rmd | 64853a2 | StephanLewandowsky | 2020-03-29 | wflow_publish(c(“analysis/index.Rmd”, “analysis/UKcov1.Rmd”)) |
1 Status of this report
These results represent a snapshot of an ongoing analysis and have not been peer-reviewed. They are for information but not for citation or to inform policy (as yet). Please report comments or bugs to stephan.lewandowsky@bristol.ac.uk or leave a comment on the relevant post on our subreddit.
Last update: Mon Feb 15 13:47:43 2021
These results are for the U.K. only. For other countries, return Home (click menu option on top) and choose another country.
2 U.K. Policy background.
- There has been a lot of recent coverage of the Big Data Institute Oxford’s contact-tracing app, which suggests things are moving quickly in policy/media discourse.
- The SPI-B evidence list from 6th March shows the public perception surveys they are using, all SAGE evidence published so far is here.
- The Coronavirus Bill did not include any provisions for wider surveillance tracing, but public health enforcement has existing widespread power to request contact data for infectious/potentially infectious persons.
- The Information Commissioners’ Office (ICO) has already said that use of mobile phone data would be legal if broader contact-tracing introduced, and that anonymous geolocation data is already being used. See here and here.
3 U.K. Wave 1 (28 & 29 March 2020)
Participants: A representative samples of 2,000 U.K. participants were recruited through the online platform Prolific. Participants were at least 18 years old. Participants were paid 85 Pence for their participation in the 10-minute study.
Preregistration: The preregistration for the study is here. It contains multiple files (under the Files menu), including the text of the preregistration and a copy of the Qualtrics source code for the study.
Data: The data are available here. Note that demographics and other variables (such as location information) that could lead to deanonymization have been omitted from the published data set. The results reported here include summaries of some of those variables.
3.1 Basic exploration
Note that the R code for this analysis can be hidden or made visible by clicking the black toggles next to each segment.
3.1.1 Setup and read data
Records 2 and 3 were manually deleted from the .csv file provided by Qualtrics to facilitate reading of the file. Records 1 and 2 of the original file were transposed into columns in a new Excel file, called varUKCovid.xlsx, which therefore summarizes the short variable names (column 1, manually labelled varname) and the accompanying full text of the item (column 2, labelled fullname).
In a non-public analysis of the raw data file, duplicate Prolific ID numbers (N=142) were identified and written to a text file. The number of duplicates may reflect the fact that, for technical reasons, the survey had to be run in two installments of 500 and 1,500 participants, respectively, with no possibility of automatic exclusion of earlier participants in the second run.
The Prolific IDs were then removed from the publicly available datafile, together with other demographics or sensitive information to preserve privacy.
# Reading data and variable names
covfn <- paste(inputdir,"UK+social+licencing+COVID.csv",sep="/") #this is the complete data file with demographics. Version on OSF does not have demographics to reduce likelihood of reidentification of respondents.
covdata <- read.csv(covfn)
# Now read variable names from the ***US*** first wave because those are the ones also used in later UK wave. We override the Wave 1 names so the analysis can
# be the same from here on irrespective of country and wave
covvarn <- read_excel(paste(inputdir,"varUSCovid.xlsx",sep="/"))
names(covdata) <- covvarn$varname #... and we now have the names updated.
#fix annoying misspelling of variables
covdata %<>% rename(is_acceptable1_sev = is_accceptable1_sev)
#read the duplicate records previously computed from the raw data set
duplicaterecs <- read.table(paste(inputdir,"dupsUK.dat",sep="/"))
#which attention check options are correct
corattcheck<-13.2 Clean up data
- Remove duplicate observations identified in a prior, private analysis.
- Remove observations that are returned as not having finished.
- Remove observations from participants who answered the fact check about the scenario incorrectly.
- Remove lots of unnecessary variables to create a lean dataset.
- Recode responses to three items (wv_lim_gov, wv_freemarket_lim, wv_freemarket_best) that were not on a 1-7 scale (Qualtrics does wild things)
- Reverse score item wv_freemarket_lim so it points towards increasing libertarianism, just like the other two.
# from here on the code is identical between waves and countries, and hence there is not much in the .Rmd files.
# all the action takes place here
# remove duplicates first because the data set has not been touched yet, so the row pointers are correct
if (!is.null(duplicaterecs)) {
covdata <- covdata [-unlist(duplicaterecs),]
}
covdata$attok <- covdata %>% select(starts_with("att_check")) %>% apply(.,1,FUN=function(x) sum(x==corattcheck,na.rm=TRUE)) #works for 1 or more attention checks
covfin <- covdata %>% filter(Finished>0) %>% filter(attok == 1) %>%
select(-c(starts_with("Recipient"),starts_with("Q_"),
Status,Finished,Progress,DistributionChannel,UserLanguage,
ResponseId,ExternalReference))
covfin$id <- 1:nrow(covfin)
covfin$scenario_type <- factor(covfin$scenario_type) #get rid of empty levels (in case of Spain, those may have arisen through merge)
#create good labels for variables (from expss package)
#some of these are moved to each .Rmd file because different countries/waves have different labels for some items
covfin <- apply_labels(covfin,
gender = "Gender",
gender = c("Male" = 1, "Female" = 2, "Other" = 3, "Prefer not to say" =4),
COVID_pos = "I tested positive to COVID",
COVID_pos = c("Yes" = 1, "No" = 0),
scenario_type = "Type of policy scenario",
COVID_lost_job = "I lost my job",
COVID_lost_job = c("Yes" = 1, "No" = 0))
################################################################################################################labels for country-specific variables
covfin <- apply_labels(covfin,
education = "Education",
education = c("GCSE" = 1, "A levels/VCE" = 2, "University" = 3, "Apprent/Vocatnl" = 11),
COVID_pos_others = "Tested pos someone I know",
COVID_pos_others = c("Yes" = 1, "No" = 0),
COVID_info_source= "Information source",
COVID_info_source = c("Newspaper (printed or online)" = 1, "Social media" = 2, "Friends/family" = 3, "Radio" = 4,
"Television" = 5))
#now deal with clean-up of Qualtrics that's unique to UK Wave 1
covfin <- covfin %>% mutate(wv_freemarket_best=ifelse(wv_freemarket_best==1,1,wv_freemarket_best-2)) %>%
mutate(wv_freemarket_lim=ifelse(wv_freemarket_lim==1,1,wv_freemarket_lim-2)) %>%
mutate(wv_lim_gov=ifelse(wv_lim_gov==1,1,wv_lim_gov-2)) %>% mutate(wv_freemarket_lim=revscore(wv_freemarket_lim,7))
#compute composite score for worldview
covfin$Worldview <- covfin %>% select(c(wv_freemarket_best, wv_freemarket_lim, wv_lim_gov)) %>% apply(.,1, mean, na.rm=TRUE)3.3 Demographics
Number of retained participants: 1810.
Gender, education, and age:
cro_tpct(covfin$gender) %>% set_caption("Gender identification: Percentages")| Gender identification: Percentages | |
| #Total | |
|---|---|
| Gender | |
| Male | 48.8 |
| Female | 51.0 |
| Other | 0.1 |
| Prefer not to say | 0.1 |
| #Total cases | 1810 |
cro_tpct(covfin$education) %>% set_caption("Level of education: Percentages")| Level of education: Percentages | |
| #Total | |
|---|---|
| Education | |
| GCSE | 15.3 |
| A levels/VCE | 17.3 |
| University | 55.7 |
| Apprent/Vocatnl | 11.7 |
| #Total cases | 1809 |
descr(covfin$age_1)Descriptive Statistics
covfin$age_1
N: 1810
age_1
----------------- ---------
Mean 45.60
Std.Dev 15.36
Min 18.00
Q1 32.00
Median 46.00
Q3 60.00
Max 100.00
MAD 20.76
IQR 28.00
CV 0.34
Skewness -0.02
SE.Skewness 0.06
Kurtosis -1.10
N.Valid 1810.00
Pct.Valid 100.00hist(covfin$age_1, xlab="Age",main="",las=1)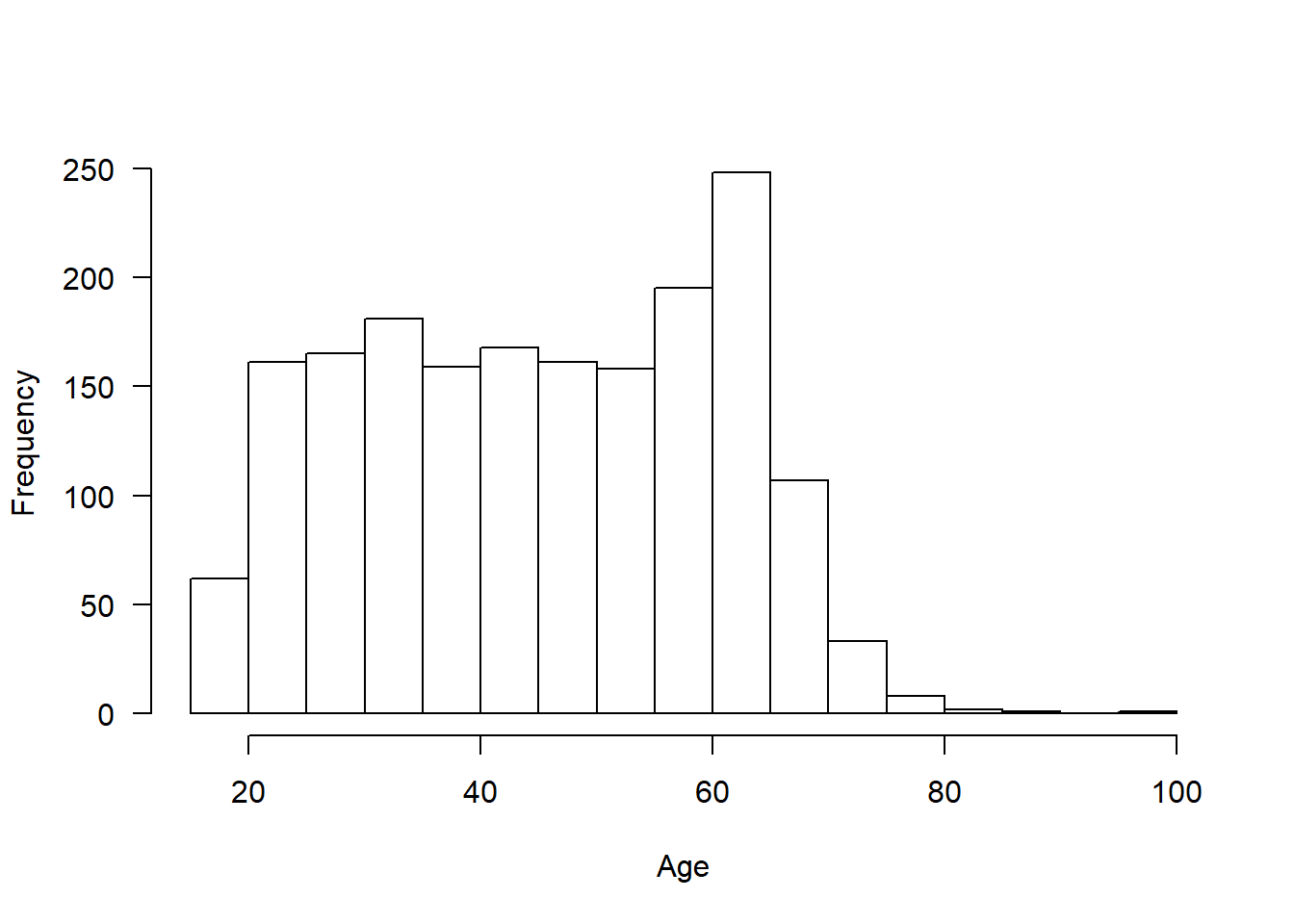
###############################################################################################################3.4 Summary of COVID related variables
How long have you been in “lockdown”?
hist(covfin$COVID_ndays_4, xlab="Days in `lockdown`",main="",las=1)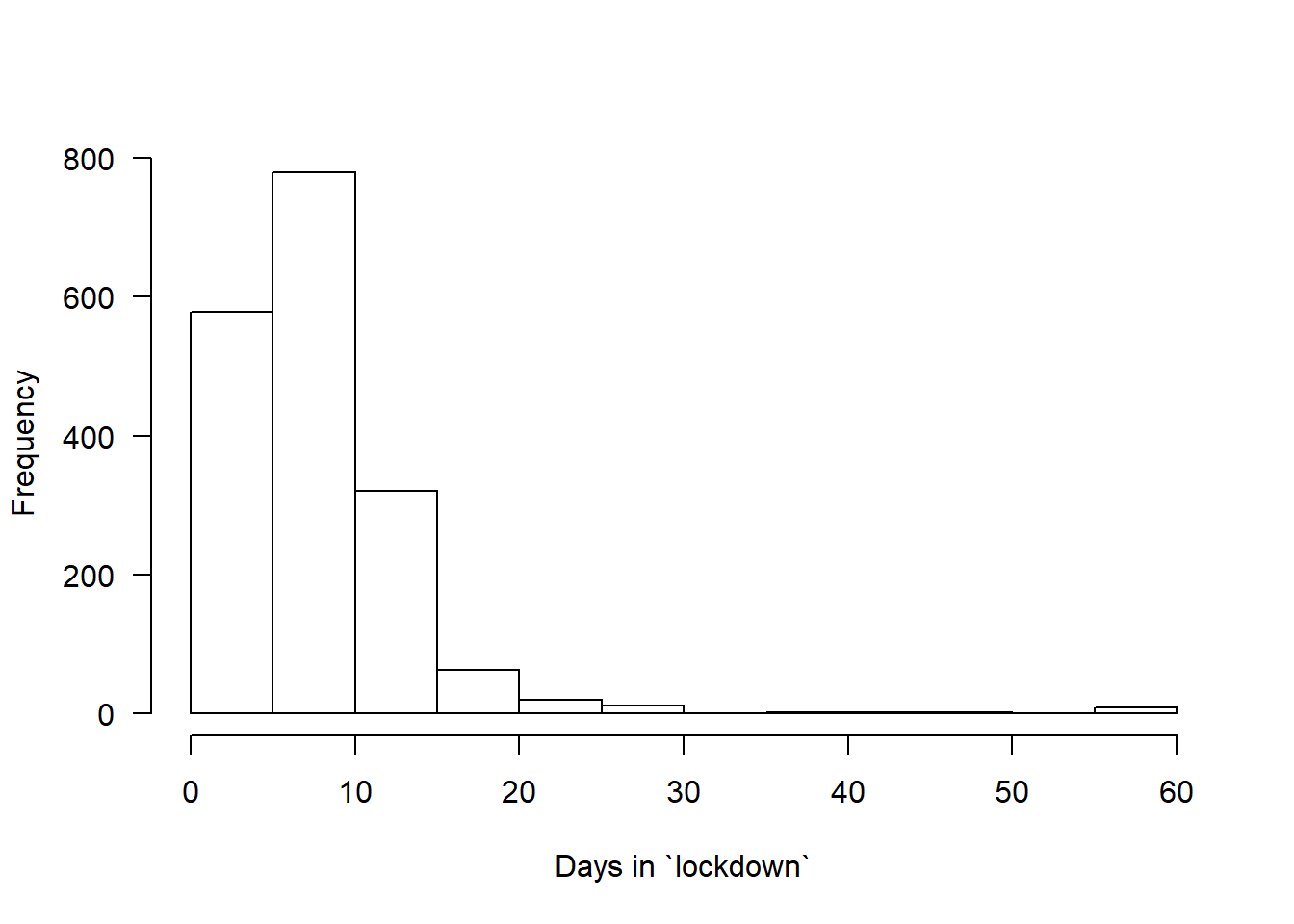
Have you, temporarily or permanently, lost your job as a consequence of the novel coronavirus (COVID-19) pandemic?
cro_tpct(covfin$COVID_lost_job) %>% set_caption("I have lost my job: Percentages")| I have lost my job: Percentages | |
| #Total | |
|---|---|
| I lost my job | |
| No | 82.9 |
| Yes | 17.1 |
| #Total cases | 1810 |
What is your main source of information about the novel coronavirus (COVID-19) pandemic?
cro_tpct(covfin$COVID_info_source) %>% set_caption("Information source: Percentages")| Information source: Percentages | |
| #Total | |
|---|---|
| Information source | |
| Newspaper (printed or online) | 30.1 |
| Social media | 13.6 |
| Friends/family | 1.5 |
| Radio | 5.0 |
| Television | 49.8 |
| #Total cases | 1810 |
Have you tested positive for COVID?
cro_tpct(covfin$COVID_pos) %>% set_caption("I tested positive for COVID-19: Percentages") | I tested positive for COVID-19: Percentages | |
| #Total | |
|---|---|
| I tested positive to COVID | |
| No | 99.6 |
| Yes | 0.4 |
| #Total cases | 1810 |
Has someone you know tested positive for COVID?
cro_tpct(covfin$COVID_pos_others) %>% set_caption("Somebody I know tested positive for COVID-19: Percentages") | Somebody I know tested positive for COVID-19: Percentages | |
| #Total | |
|---|---|
| Tested pos someone I know | |
| No | 89.8 |
| Yes | 10.2 |
| #Total cases | 1810 |
There are 4 items probing people’s COVID risk perception:
- How severe do you think novel coronavirus (COVID-19) will be in the population as a whole?
- How harmful would it be for your health if you were to become infected with COVID-19?
- How concerned are you that you might become infected with COVID-19?
- How concerned are you that somebody you know might become infected with novel?
Provide snapshot of responses and correlations between items.
covvars<-gather(covfin %>% select(c(COVID_gen_harm,COVID_pers_harm,COVID_pers_concern,COVID_concern_oth)),factor_key = TRUE)
covvars$key <- factor(covvars$key,labels=c("General harm","Personal harm","Concern self","Concern others"))
covhisto <- ggplot(covvars, aes(value)) +
theme_classic() +
theme(panel.grid.minor.y = element_line(colour="lightgray", size=0.5),
panel.grid.major.y = element_line(colour="darkgray", size=0.5),
panel.grid.major.x = element_blank(),
panel.border = element_rect(colour = "black", size=1, fill=NA)) +
geom_histogram(bins = 5, color="darkblue", fill="lightblue") +
xlab("Response") + ylab("Frequency") +
facet_wrap(~key, scales = 'free_x',labeller=label_value)
ggsave("covhisto.pdf")Saving 7 x 5 in imageprint(covhisto)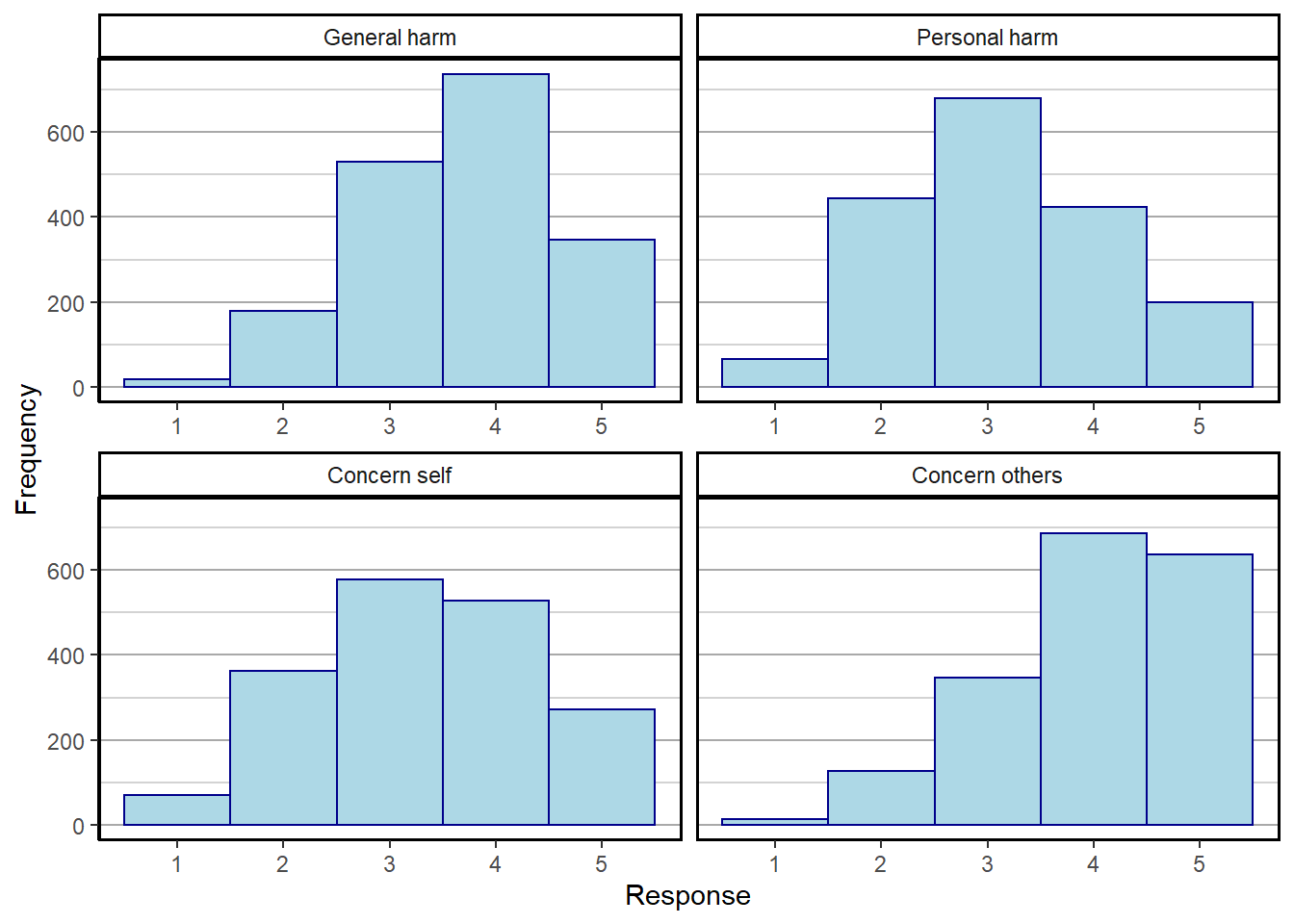
covfin %>% select(c(COVID_gen_harm,COVID_pers_harm,COVID_pers_concern,COVID_concern_oth)) %>% cor (.,use="pairwise.complete.obs") %>% round(.,3) COVID_gen_harm COVID_pers_harm COVID_pers_concern
COVID_gen_harm 1.000 0.427 0.443
COVID_pers_harm 0.427 1.000 0.599
COVID_pers_concern 0.443 0.599 1.000
COVID_concern_oth 0.390 0.385 0.644
COVID_concern_oth
COVID_gen_harm 0.390
COVID_pers_harm 0.385
COVID_pers_concern 0.644
COVID_concern_oth 1.000#compute composite score for COVID risk
covfin$COVIDrisk <- covfin %>% select(c(COVID_gen_harm,COVID_pers_harm,COVID_pers_concern,COVID_concern_oth)) %>% apply(.,1, mean, na.rm=TRUE)
#compute composite score for government trust
covfin$govtrust <- covfin %>% select(starts_with("trus")) %>% apply(.,1, mean, na.rm=TRUE)
###############################################################################################################4 Comparison between scenarios
4.1 Acceptability of policy
Not all items are entirely commensurate between scenarios. We begin with a graphical summary. The figure below shows people’s confidence that each of the scenarios would:
- reduce their likelihood of contracting COVID-19
- allow them to resume their normal lives more rapidly
- reduce spread of COVID-19 in the community.
#plot violins side by side
plotvn <- c("Reduce contracting","Resume normal","Reduce spread")
vioplot(select(covfin,c(reduce_lik_mild,return_activ_mild,reduce_spread_mild)), col = "yellow", plotCentre = "line", side = "left",
las=1,names=plotvn,ylim=c(1,7.5))
vioplot(select(covfin,c(reduce_lik_sev,return_activ_sev,reduce_spread_severe)), col = "red", plotCentre = "line", side = "right", add = T )
title(xlab="Variable",ylab="Confidence")
legend(3,7.6, fill = c("yellow", "red"), legend = c("Mild", "Severe"), title = "Type of scenario")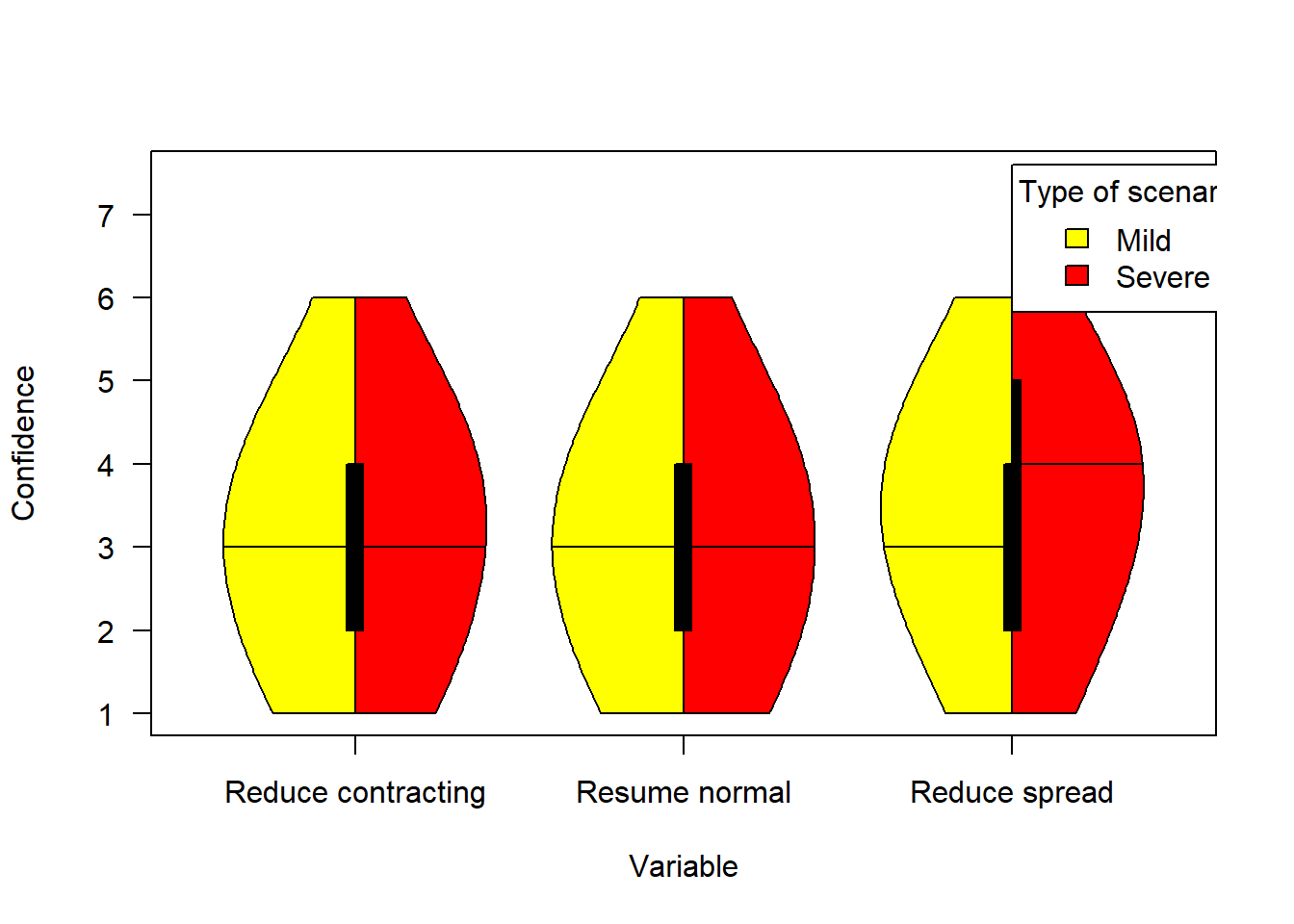
###############################################################################################################Basic acceptability of each scenario, probed by a single item immediately after reading the scenario. The table shows percentages. For the mild scenario, the question refers to whether participant would download the app. For the severe scenario, the question refers to acceptability of the tracking mandated by government.
covfin$accept1 <- apply(cbind(covfin$app_uptake1_mild,covfin$is_acceptable1_sev),1,sum,na.rm=TRUE)
covfin <- apply_labels(covfin,
accept1 = "Acceptability of policy",
accept1 = c("Yes" = 1, "No" = 0),
scenario_type = "Type of scenario")
cro_tpct(covfin$accept1,row_vars=covfin$scenario_type)| #Total | |||
|---|---|---|---|
| Type of scenario | |||
| mild | Acceptability of policy | No | 29.9 |
| Yes | 70.1 | ||
| #Total cases | 890 | ||
| severe | Acceptability of policy | No | 33.8 |
| Yes | 66.2 | ||
| #Total cases | 920 | ||
chisq.test(covfin$accept1,covfin$scenario_type,correct=TRUE)
Pearson's Chi-squared test with Yates' continuity correction
data: covfin$accept1 and covfin$scenario_type
X-squared = 3.0178, df = 1, p-value = 0.08235###############################################################################################################The difference between acceptability of scenarios is not significant by a \(\chi^2\) test on the contingency table.
Repeated probing of basic acceptability of each scenario after multiple questions about the scenario have been answered. The table shows percentages. For the mild scenario, the question refers to whether participant would download the app. For the severe scenario, the question refers to acceptability of the tracking mandated by government.
covfin$accept2 <- apply(cbind(covfin$app_uptake2_mild,covfin$is_acceptable2_sev),1,sum,na.rm=TRUE)
covfin <- apply_labels(covfin,
accept2 = "Acceptability of policy",
accept2 = c("Yes" = 1, "No" = 0),
scenario_type = "Type of scenario")
cro_tpct(covfin$accept2,row_vars=covfin$scenario_type)| #Total | |||
|---|---|---|---|
| Type of scenario | |||
| mild | Acceptability of policy | No | 31.3 |
| Yes | 68.7 | ||
| #Total cases | 890 | ||
| severe | Acceptability of policy | No | 36.2 |
| Yes | 63.8 | ||
| #Total cases | 920 | ||
chisq.test(covfin$accept2,covfin$scenario_type,correct=TRUE)
Pearson's Chi-squared test with Yates' continuity correction
data: covfin$accept2 and covfin$scenario_type
X-squared = 4.5354, df = 1, p-value = 0.0332###############################################################################################################The difference between acceptability of scenarios is now significant by a \(\chi^2\) test, and overall acceptability of both scenarios has been reduced slightly compared to first set of questions.
Those people who found the scenario unacceptable at the second opportunity were asked two follow-up questions. Those questions were as follows:
First, for both scenarios, people were asked if their decision would change if the government was required to delete the data and cease tracking after 6 months. Responses to this sunset question (percentages) were as follows:
covfin$accept3 <- apply(cbind(covfin$accept2,covfin %>% select(contains("sunset"))),1,sum,na.rm=TRUE)
covfin <- apply_labels(covfin,
accept3 = "Acceptability of policy",
accept3 = c("Yes" = 1, "No" = 0),
scenario_type = "Type of scenario")
cro_tpct(covfin$accept3,row_vars=covfin$scenario_type)| #Total | |||
|---|---|---|---|
| Type of scenario | |||
| mild | Acceptability of policy | No | 22.1 |
| Yes | 77.9 | ||
| #Total cases | 890 | ||
| severe | Acceptability of policy | No | 24.0 |
| Yes | 76.0 | ||
| #Total cases | 920 | ||
chisq.test(covfin$accept3,covfin$scenario_type,correct=TRUE)
Pearson's Chi-squared test with Yates' continuity correction
data: covfin$accept3 and covfin$scenario_type
X-squared = 0.80373, df = 1, p-value = 0.37###############################################################################################################The sunset clause increased acceptability of the scenario, although some opposition remained.
The second follow-up question differed between scenarios. People in the mild scenario were asked if they would change their decision if data was stored only on the user’s smartphone (not government servers), and people were given the option to provide the data if they tested positive. People in the severe scenario were asked if they would change their decision if there was an option to opt out of data collection.
covfin$accept5 <- apply(cbind(covfin$accept2,covfin %>% select(contains("sunset")),
covfin$change_dlocal_mild,covfin$change_optout_sev),1,max,na.rm=TRUE)
covfin <- apply_labels(covfin,
accept5 = "Acceptability of policy",
accept5 = c("Yes" = 1, "No" = 0),
scenario_type = "Type of scenario")
cro_tpct(covfin$accept5,row_vars=covfin$scenario_type)| #Total | |||
|---|---|---|---|
| Type of scenario | |||
| mild | Acceptability of policy | No | 14.5 |
| Yes | 85.5 | ||
| #Total cases | 890 | ||
| severe | Acceptability of policy | No | 12.5 |
| Yes | 87.5 | ||
| #Total cases | 920 | ||
chisq.test(covfin$accept5,covfin$scenario_type,correct=TRUE)
Pearson's Chi-squared test with Yates' continuity correction
data: covfin$accept5 and covfin$scenario_type
X-squared = 1.3765, df = 1, p-value = 0.2407###############################################################################################################The opt-out/local storage options further enhanced acceptance.
4.2 Assessment of risk of scenarios, trust in government and data security
The next graph shows responses to the following items (abridged from survey):
- How difficult is it for people to decline participation in the proposed project? (1 = Extremely easy – 6 = Extremely difficult)
- To what extent is the Government only collecting the data necessary? (1 = Not at all – 6 = Completely)
- How sensitive is the data being collected in the proposed project? (1 = Not at all – 6 = Extremely)
- How serious is the risk of harm that could arise from the proposed project? (1 = Not at all – 6 = Extremely)
- How much do you trust the Government to use the tracking data only to deal with the COVID-19 pandemic? (1 = Not at all – 6 = Completely)
- How much do you trust the Government to be able to ensure the privacy of each individual? (1 = Not at all – 6 = Completely)
- How secure is the data that would be collected for the proposed project? (1 = Not at all – 6 = Completely)
- To what extent do people have ongoing control of their data? (1 = No control at all – 6 = Complete control)
#plot violins side by side
#x11(width=10,height=6)
plotvn <- c("Decline","Necessary","Sensitive","Risk","Trust use","Trust privacy","Secure", "Control")
vioplot(select(filter(covfin,scenario_type=="mild"),c(decline_participate:ongoing_control)), col = "yellow", plotCentre = "line", side = "left",
las=1,names=plotvn,ylim=c(1,7.5))
vioplot(select(filter(covfin,scenario_type=="severe"),c(decline_participate:ongoing_control)), col = "red", plotCentre = "line", side = "right", add = T )
title(xlab="Variable",ylab="Response")
legend(3,7.6, fill = c("yellow", "red"), legend = c("Mild", "Severe"), title = "Type of scenario")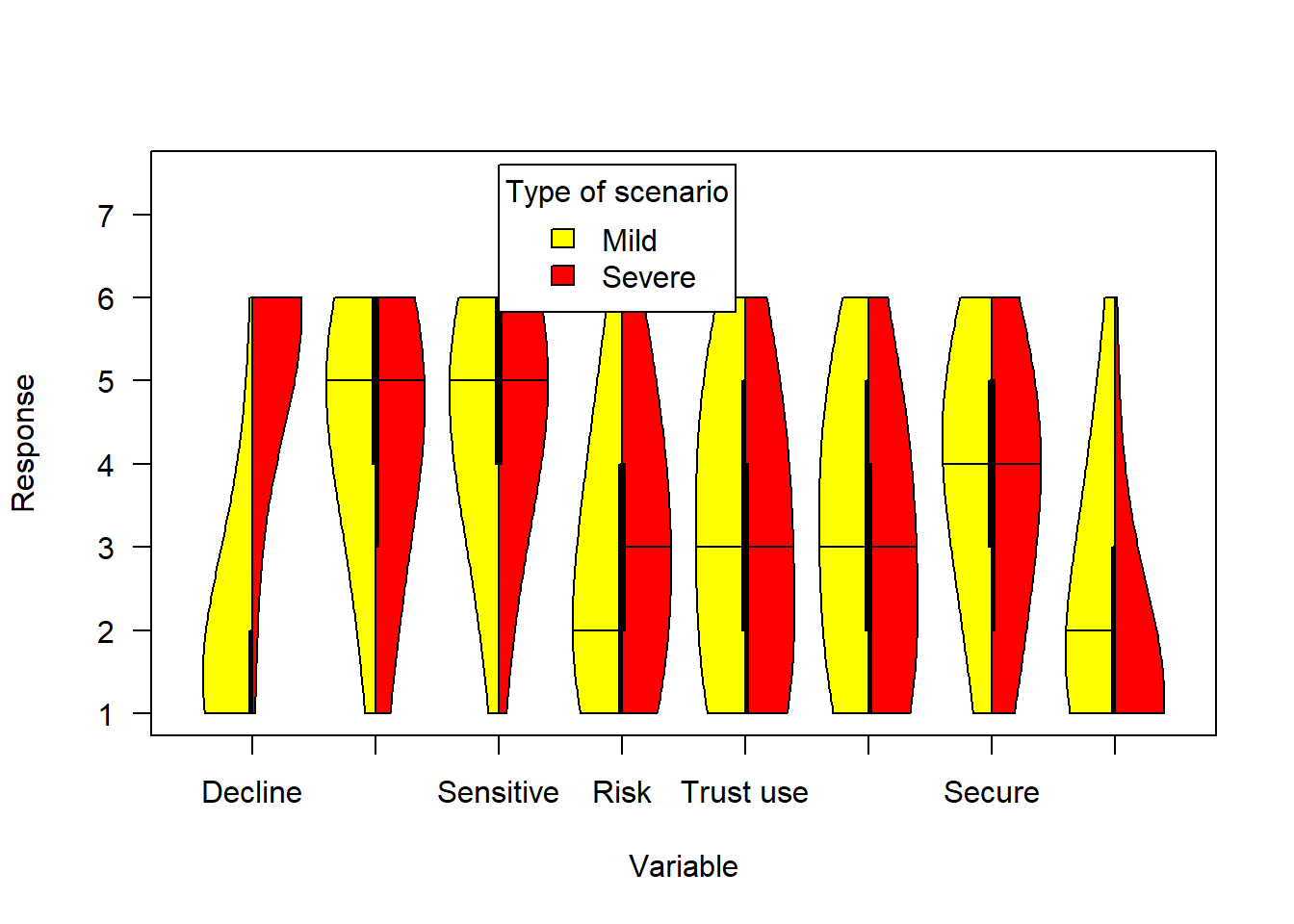
###############################################################################################################5 Role of worldviews
5.1 Worldview and risk perception
We relate a composite of the 3 worldview items to the composite of the 4 items probing perceived risk from COVID. Worldview is scored such that greater values reflect greater libertarianism.
p <- ggplot(covfin, aes(Worldview, COVIDrisk)) +
geom_point(size=1.5,shape = 21,fill="red",
position=position_jitter(width=0.15, height=0.15)) +
geom_smooth() +
theme(plot.title = element_text(size = 18),
panel.background = element_rect(fill = "white", colour = "grey50"),
text = element_text(size=14)) +
xlim(0.8,7.2) + ylim(0.8,5.2) +
labs(x="Worldview (libertarianism)", y="Perceived COVID risk")
print(p)`geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'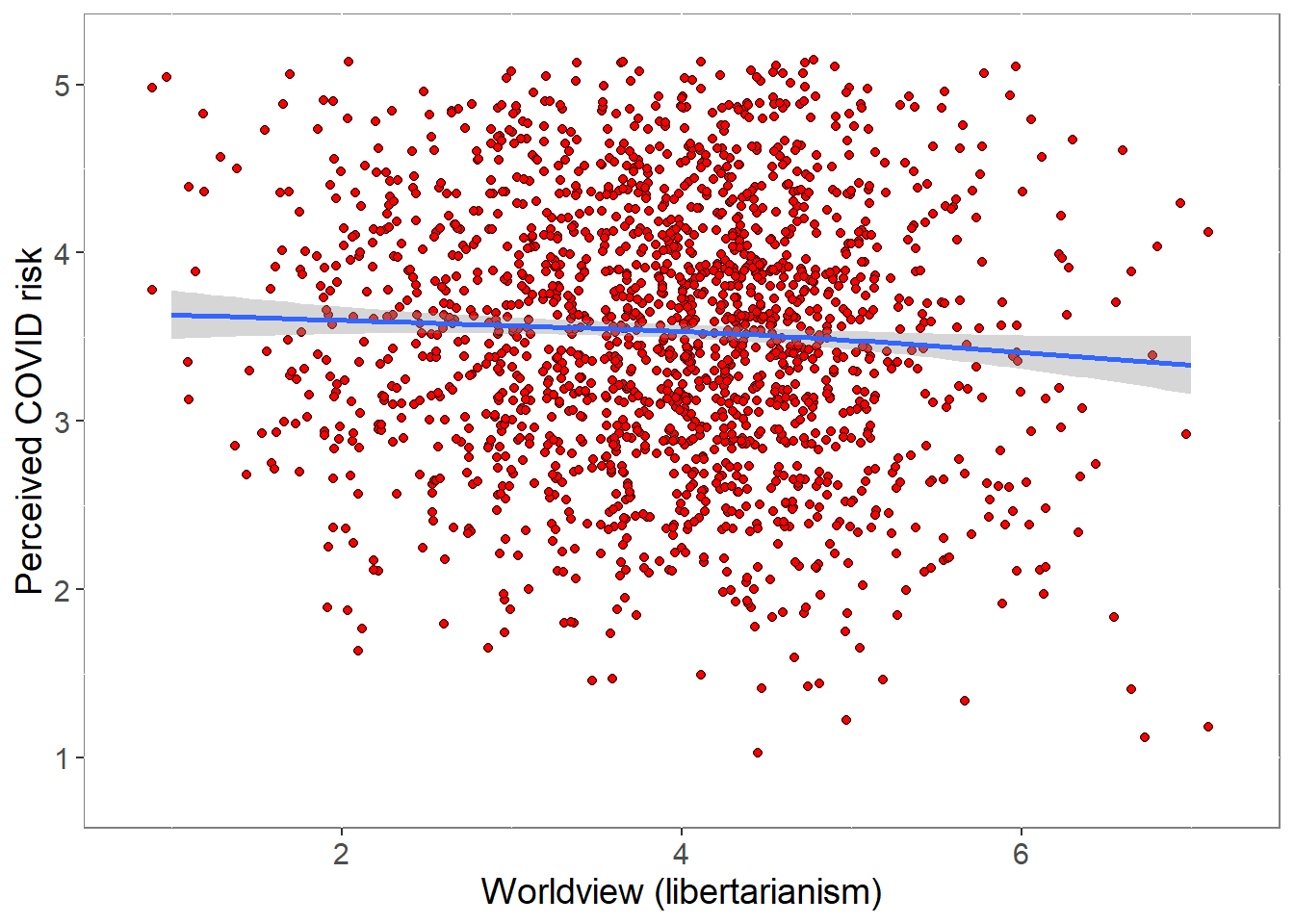
pcor <- cor.test (covfin$Worldview,covfin$COVIDrisk, use="pairwise.complete.obs") %>% print()
Pearson's product-moment correlation
data: covfin$Worldview and covfin$COVIDrisk
t = -2.7115, df = 1808, p-value = 0.006762
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.10939272 -0.01761596
sample estimates:
cor
-0.0636389 ###############################################################################################################There is a small, but statistically significant correlation between worldviews and risk perception, such that greater libertarianism is (just) associated with reduced risk perception. The variance accounted for (0.004) is minimal.
5.2 Worldviews and trust
We relate the composite of the 3 worldview items to the composite of the two trust-in-government items (which correlate 0.842).
p <- ggplot(covfin, aes(Worldview, govtrust)) +
geom_point(size=1.5,shape = 21,fill="red",
position=position_jitter(width=0.15, height=0.15)) +
geom_smooth() +
theme(plot.title = element_text(size = 18),
panel.background = element_rect(fill = "white", colour = "grey50"),
text = element_text(size=14)) +
xlim(0.8,7.2) + ylim(0.8,5.2) +
labs(x="Worldview (libertarianism)", y="Trust in government")
print(p)`geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'Warning: Removed 145 rows containing non-finite values (stat_smooth).Warning: Removed 145 rows containing missing values (geom_point).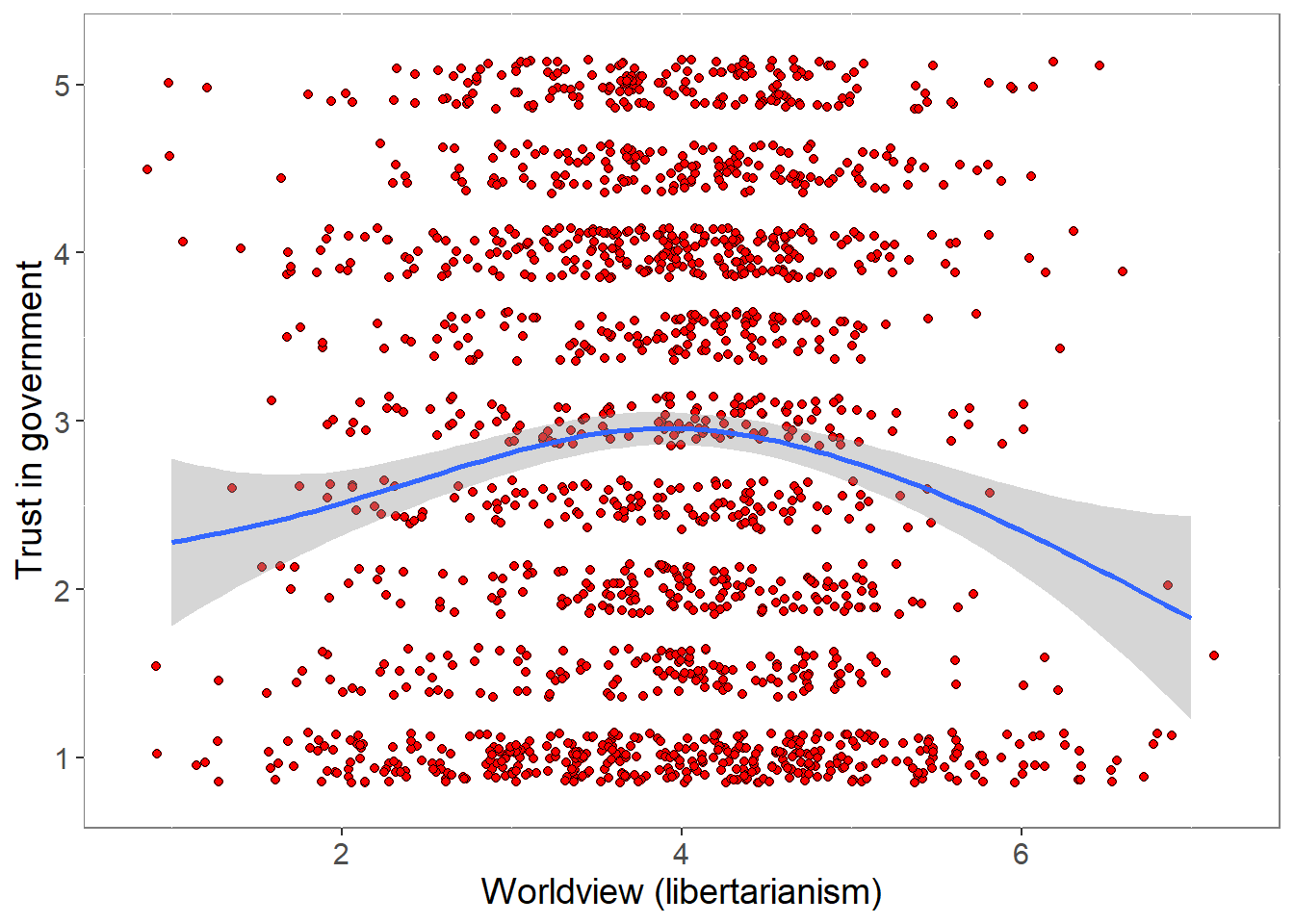
pcor <- cor.test (covfin$Worldview,covfin$govtrust, use="pairwise.complete.obs") %>% print()
Pearson's product-moment correlation
data: covfin$Worldview and covfin$govtrust
t = 0.74751, df = 1808, p-value = 0.4549
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.02852043 0.06360033
sample estimates:
cor
0.01757725 ###############################################################################################################The pattern is suggestive of the possibility that trust in government is less at both extremes of the ideological scale.
6 Logistic modeling
We now try to model acceptability of the scenarios from some of the other variables using logistic regression. The models were initially developed by Dan Little, imported and extended by Stephan Lewandowsky on 7 April 2020.
6.1 Mixed-effects modeling
The first model is a mixed-effects model. This includes a random intercept (i.e., a different intercept for each participant). The model used the various trust variables and other questions about the policies being proposed.
lrmod1 <- glmer(accept1 ~ decline_participate + proportionality + sensitivity + risk_of_harm + trust_intentions + trust_respect_priv + scenario_type + (1 | id),
data = covfin %>% mutate(accept1=unlabel(accept1)) %>% mutate(scenario_type=unlabel(scenario_type)), family = binomial)boundary (singular) fit: see ?isSingularsumm(lrmod1,digits=3)Warning in summ.merMod(lrmod1, digits = 3): Could not calculate r-squared. Try removing missing data
before fitting the model.| Observations | 1810 |
| Dependent variable | accept1 |
| Type | Mixed effects generalized linear model |
| Family | binomial |
| Link | logit |
| AIC | 1557.372 |
| BIC | 1606.882 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -1.896 | 0.362 | -5.234 | 0.000 |
| decline_participate | -0.039 | 0.061 | -0.645 | 0.519 |
| proportionality | 0.340 | 0.049 | 6.934 | 0.000 |
| sensitivity | -0.071 | 0.055 | -1.280 | 0.201 |
| risk_of_harm | -0.183 | 0.049 | -3.766 | 0.000 |
| trust_intentions | 0.444 | 0.071 | 6.248 | 0.000 |
| trust_respect_priv | 0.358 | 0.071 | 5.019 | 0.000 |
| scenario_typesevere | 0.356 | 0.264 | 1.348 | 0.178 |
| Group | Parameter | Std. Dev. |
|---|---|---|
| id | (Intercept) | 0.000 |
| Group | # groups | ICC |
|---|---|---|
| id | 1810 | 0.000 |
#try a different optimizer to see if singularity persists
ss <- getME(lrmod1,c("theta","fixef"))
lrmod1a <- update(lrmod1,start=ss,control=glmerControl(optimizer="bobyqa", optCtrl=list(maxfun=2e5)))boundary (singular) fit: see ?isSingularsumm(lrmod1a,digits=3)Warning in summ.merMod(lrmod1a, digits = 3): Could not calculate r-squared. Try removing missing data
before fitting the model.| Observations | 1810 |
| Dependent variable | accept1 |
| Type | Mixed effects generalized linear model |
| Family | binomial |
| Link | logit |
| AIC | 1557.372 |
| BIC | 1606.882 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -1.896 | 0.362 | -5.234 | 0.000 |
| decline_participate | -0.039 | 0.061 | -0.645 | 0.519 |
| proportionality | 0.340 | 0.049 | 6.934 | 0.000 |
| sensitivity | -0.071 | 0.055 | -1.280 | 0.201 |
| risk_of_harm | -0.183 | 0.049 | -3.766 | 0.000 |
| trust_intentions | 0.444 | 0.071 | 6.248 | 0.000 |
| trust_respect_priv | 0.358 | 0.071 | 5.019 | 0.000 |
| scenario_typesevere | 0.356 | 0.264 | 1.348 | 0.178 |
| Group | Parameter | Std. Dev. |
|---|---|---|
| id | (Intercept) | 0.000 |
| Group | # groups | ICC |
|---|---|---|
| id | 1810 | 0.000 |
#use composite score for trust
covfin$trust <- (covfin$proportionality + covfin$trust_intentions + covfin$trust_respect_priv)/3
lrmod1b <- glmer(accept1 ~ decline_participate + sensitivity + risk_of_harm + trust + scenario_type + (1 | id),
data = covfin %>% mutate(accept1=unlabel(accept1)) %>% mutate(scenario_type=unlabel(scenario_type)), family = binomial)boundary (singular) fit: see ?isSingularsumm(lrmod1b,digits=3)Warning in summ.merMod(lrmod1b, digits = 3): Could not calculate r-squared. Try removing missing data
before fitting the model.| Observations | 1810 |
| Dependent variable | accept1 |
| Type | Mixed effects generalized linear model |
| Family | binomial |
| Link | logit |
| AIC | 1554.709 |
| BIC | 1593.217 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -1.964 | 0.356 | -5.509 | 0.000 |
| decline_participate | -0.041 | 0.061 | -0.681 | 0.496 |
| sensitivity | -0.080 | 0.055 | -1.454 | 0.146 |
| risk_of_harm | -0.180 | 0.048 | -3.710 | 0.000 |
| trust | 1.152 | 0.064 | 17.949 | 0.000 |
| scenario_typesevere | 0.367 | 0.264 | 1.393 | 0.164 |
| Group | Parameter | Std. Dev. |
|---|---|---|
| id | (Intercept) | 0.000 |
| Group | # groups | ICC |
|---|---|---|
| id | 1810 | 0.000 |
###############################################################################################################It is clear that the singularity is caused by the near-zero random-effects variance and seems quite resistant to a few attempts to get around it. The remaining models therefore drop the random effect.
6.2 Ordinary logistic regression
6.2.1 Acceptance as a function of trust in government and perceived consequences of policies
The two models are for the two acceptance/uptake questions: The first model is for the first question early on in the piece, and the second model is for the question provided later on, after all the various questions about trust have been answered.
mod1 <- glm(accept1 ~ decline_participate + proportionality + sensitivity + risk_of_harm + trust_intentions + trust_respect_priv + scenario_type,
data = covfin %>% mutate(accept1=unlabel(accept1)) %>% mutate(scenario_type=unlabel(scenario_type)), family = binomial)
summ(mod1,digits=3)| Observations | 1810 |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(7) | 726.566 |
| Pseudo-R² (Cragg-Uhler) | 0.463 |
| Pseudo-R² (McFadden) | 0.321 |
| AIC | 1555.372 |
| BIC | 1599.381 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -1.896 | 0.362 | -5.234 | 0.000 |
| decline_participate | -0.039 | 0.061 | -0.645 | 0.519 |
| proportionality | 0.340 | 0.049 | 6.934 | 0.000 |
| sensitivity | -0.071 | 0.055 | -1.280 | 0.201 |
| risk_of_harm | -0.183 | 0.049 | -3.766 | 0.000 |
| trust_intentions | 0.444 | 0.071 | 6.248 | 0.000 |
| trust_respect_priv | 0.358 | 0.071 | 5.019 | 0.000 |
| scenario_typesevere | 0.356 | 0.264 | 1.348 | 0.178 |
| Standard errors: MLE |
summ(mod1,digits=3,scale=TRUE)| Observations | 1810 |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(7) | 726.566 |
| Pseudo-R² (Cragg-Uhler) | 0.463 |
| Pseudo-R² (McFadden) | 0.321 |
| AIC | 1555.372 |
| BIC | 1599.381 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 1.050 | 0.153 | 6.880 | 0.000 |
| decline_participate | -0.087 | 0.134 | -0.645 | 0.519 |
| proportionality | 0.498 | 0.072 | 6.934 | 0.000 |
| sensitivity | -0.095 | 0.074 | -1.280 | 0.201 |
| risk_of_harm | -0.285 | 0.076 | -3.766 | 0.000 |
| trust_intentions | 0.747 | 0.120 | 6.248 | 0.000 |
| trust_respect_priv | 0.578 | 0.115 | 5.019 | 0.000 |
| scenario_type | 0.356 | 0.264 | 1.348 | 0.178 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod1, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)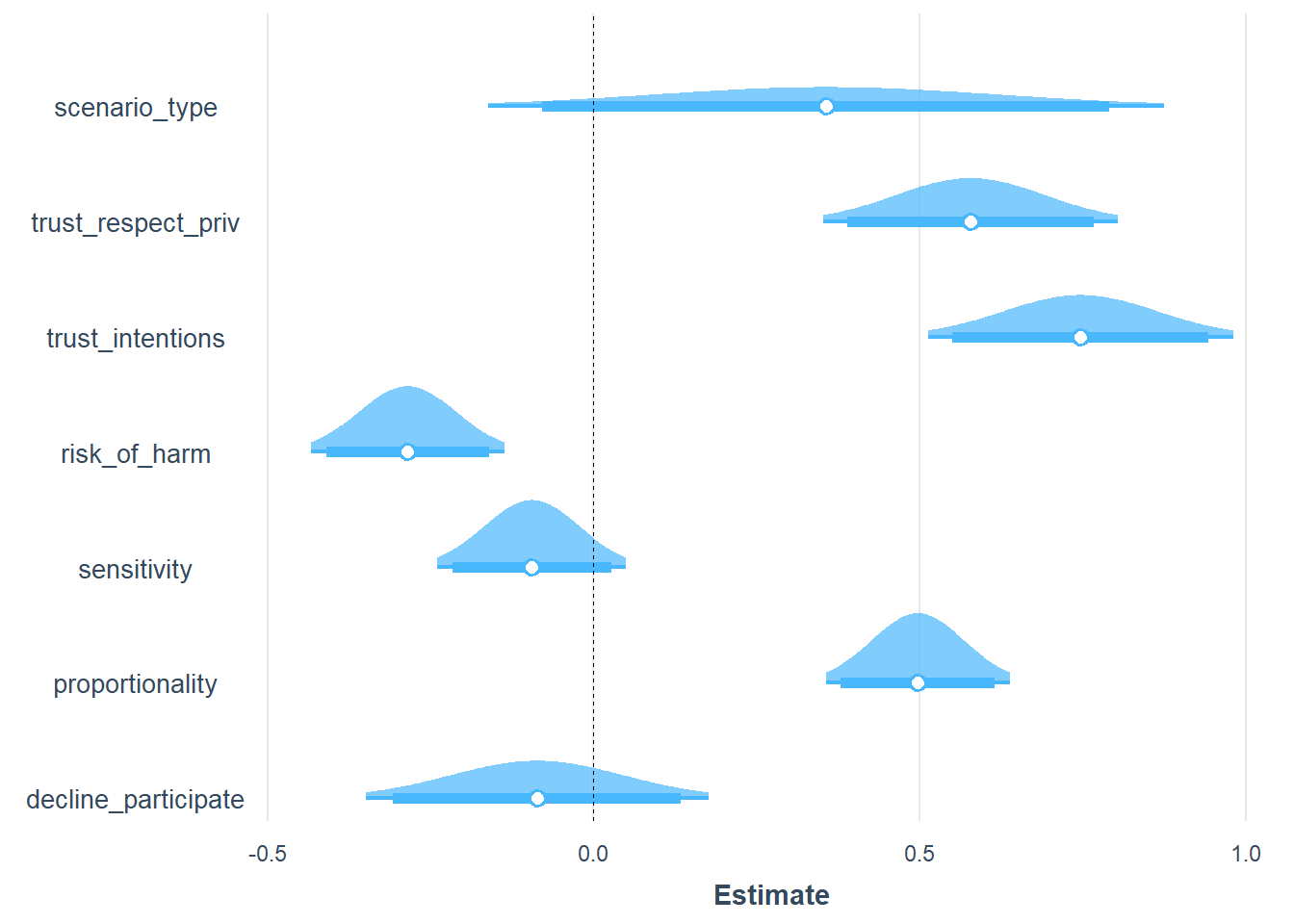
mod2 <- glm(accept2 ~ decline_participate + proportionality + sensitivity + risk_of_harm + trust_intentions + trust_respect_priv + scenario_type,
data = covfin %>% mutate(accept2=unlabel(accept2)) %>% mutate(scenario_type=unlabel(scenario_type)), family = binomial)
summ(mod2,digits=3)| Observations | 1810 |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(7) | 788.047 |
| Pseudo-R² (Cragg-Uhler) | 0.489 |
| Pseudo-R² (McFadden) | 0.340 |
| AIC | 1543.963 |
| BIC | 1587.972 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -2.211 | 0.365 | -6.053 | 0.000 |
| decline_participate | -0.043 | 0.061 | -0.705 | 0.481 |
| proportionality | 0.324 | 0.050 | 6.522 | 0.000 |
| sensitivity | -0.018 | 0.055 | -0.333 | 0.739 |
| risk_of_harm | -0.213 | 0.049 | -4.347 | 0.000 |
| trust_intentions | 0.496 | 0.071 | 7.034 | 0.000 |
| trust_respect_priv | 0.359 | 0.070 | 5.094 | 0.000 |
| scenario_typesevere | 0.317 | 0.266 | 1.193 | 0.233 |
| Standard errors: MLE |
summ(mod2,digits=3,scale=TRUE)| Observations | 1810 |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(7) | 788.047 |
| Pseudo-R² (Cragg-Uhler) | 0.489 |
| Pseudo-R² (McFadden) | 0.340 |
| AIC | 1543.963 |
| BIC | 1587.972 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.970 | 0.153 | 6.322 | 0.000 |
| decline_participate | -0.095 | 0.135 | -0.705 | 0.481 |
| proportionality | 0.474 | 0.073 | 6.522 | 0.000 |
| sensitivity | -0.025 | 0.074 | -0.333 | 0.739 |
| risk_of_harm | -0.331 | 0.076 | -4.347 | 0.000 |
| trust_intentions | 0.835 | 0.119 | 7.034 | 0.000 |
| trust_respect_priv | 0.580 | 0.114 | 5.094 | 0.000 |
| scenario_type | 0.317 | 0.266 | 1.193 | 0.233 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod2, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)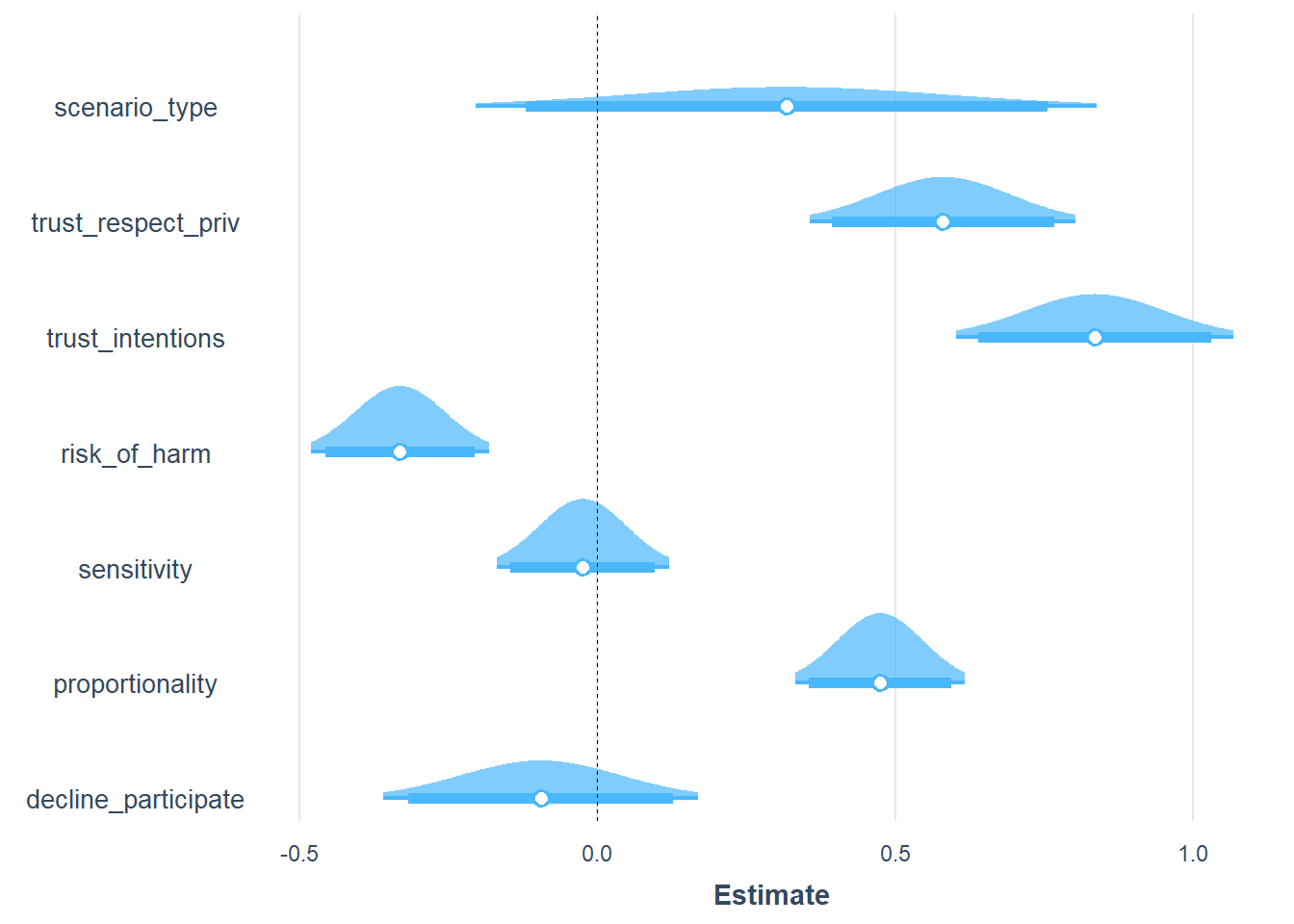
###############################################################################################################The type of scenario has no effect, but acceptance increases with trust in government and declines with perceived risk of harm from the policy. The pattern is consistent across the two opportunities to express an opinion on acceptance.
6.2.2 Acceptance as a function of perceived severity of COVID
The models again target the two acceptance/uptake items in turn. The predictors are all the COVID-related items, including days in lockdown and job loss and so on.
mod3 <- glm(accept1 ~ COVID_gen_harm + COVID_pers_harm + COVID_pers_concern + COVID_concern_oth + COVID_pos + COVID_pos_others + COVID_ndays_4 + COVID_lost_job + scenario_type, data = covfin, family = binomial)
summ(mod3,digits=3)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(9) | 72.437 |
| Pseudo-R² (Cragg-Uhler) | 0.056 |
| Pseudo-R² (McFadden) | 0.032 |
| AIC | 2177.578 |
| BIC | 2232.450 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -0.842 | 0.268 | -3.140 | 0.002 |
| COVID_gen_harm | 0.239 | 0.064 | 3.706 | 0.000 |
| COVID_pers_harm | -0.026 | 0.066 | -0.401 | 0.689 |
| COVID_pers_concern | 0.224 | 0.073 | 3.049 | 0.002 |
| COVID_concern_oth | 0.086 | 0.070 | 1.224 | 0.221 |
| COVID_pos | 0.349 | 0.857 | 0.407 | 0.684 |
| COVID_pos_others | -0.156 | 0.172 | -0.907 | 0.364 |
| COVID_ndays_4 | -0.012 | 0.008 | -1.510 | 0.131 |
| COVID_lost_job | -0.140 | 0.136 | -1.024 | 0.306 |
| scenario_typesevere | -0.198 | 0.104 | -1.906 | 0.057 |
| Standard errors: MLE |
summ(mod3,digits=3,scale=TRUE)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(9) | 72.437 |
| Pseudo-R² (Cragg-Uhler) | 0.056 |
| Pseudo-R² (McFadden) | 0.032 |
| AIC | 2177.578 |
| BIC | 2232.450 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.940 | 0.082 | 11.486 | 0.000 |
| COVID_gen_harm | 0.221 | 0.060 | 3.706 | 0.000 |
| COVID_pers_harm | -0.027 | 0.067 | -0.401 | 0.689 |
| COVID_pers_concern | 0.240 | 0.079 | 3.049 | 0.002 |
| COVID_concern_oth | 0.082 | 0.067 | 1.224 | 0.221 |
| COVID_pos | 0.349 | 0.857 | 0.407 | 0.684 |
| COVID_pos_others | -0.156 | 0.172 | -0.907 | 0.364 |
| COVID_ndays_4 | -0.077 | 0.051 | -1.510 | 0.131 |
| COVID_lost_job | -0.140 | 0.136 | -1.024 | 0.306 |
| scenario_type | -0.198 | 0.104 | -1.906 | 0.057 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
###############################################################################################################People are more likely to accept policies if they perceive greater potential for societal harm and higher personal concern. Because there was a marginal effect of scenario type, we next explore interactions.
mod4 <- glm(accept1 ~ COVID_gen_harm + COVID_pers_harm + COVID_pers_concern + COVID_concern_oth + COVID_pos + COVID_pos_others +
COVID_ndays_4 + COVID_lost_job + scenario_type + scenario_type:COVID_gen_harm + scenario_type:COVID_pers_concern,
data = covfin, family = binomial)
summ(mod4,digits=3)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(11) | 79.240 |
| Pseudo-R² (Cragg-Uhler) | 0.061 |
| Pseudo-R² (McFadden) | 0.036 |
| AIC | 2174.775 |
| BIC | 2240.621 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -0.303 | 0.347 | -0.873 | 0.383 |
| COVID_gen_harm | 0.079 | 0.093 | 0.842 | 0.400 |
| COVID_pers_harm | -0.025 | 0.066 | -0.385 | 0.700 |
| COVID_pers_concern | 0.232 | 0.092 | 2.506 | 0.012 |
| COVID_concern_oth | 0.089 | 0.071 | 1.256 | 0.209 |
| COVID_pos | 0.432 | 0.854 | 0.506 | 0.613 |
| COVID_pos_others | -0.151 | 0.172 | -0.877 | 0.380 |
| COVID_ndays_4 | -0.013 | 0.008 | -1.553 | 0.121 |
| COVID_lost_job | -0.131 | 0.137 | -0.959 | 0.337 |
| scenario_typesevere | -1.245 | 0.449 | -2.775 | 0.006 |
| COVID_gen_harm:scenario_typesevere | 0.298 | 0.125 | 2.383 | 0.017 |
| COVID_pers_concern:scenario_typesevere | -0.006 | 0.109 | -0.052 | 0.959 |
| Standard errors: MLE |
summ(mod4,digits=3,scale=TRUE)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(11) | 79.240 |
| Pseudo-R² (Cragg-Uhler) | 0.061 |
| Pseudo-R² (McFadden) | 0.036 |
| AIC | 2174.775 |
| BIC | 2240.621 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.925 | 0.082 | 11.323 | 0.000 |
| COVID_gen_harm | 0.073 | 0.086 | 0.842 | 0.400 |
| COVID_pers_harm | -0.026 | 0.068 | -0.385 | 0.700 |
| COVID_pers_concern | 0.249 | 0.099 | 2.506 | 0.012 |
| COVID_concern_oth | 0.084 | 0.067 | 1.256 | 0.209 |
| COVID_pos | 0.432 | 0.854 | 0.506 | 0.613 |
| COVID_pos_others | -0.151 | 0.172 | -0.877 | 0.380 |
| COVID_ndays_4 | -0.079 | 0.051 | -1.553 | 0.121 |
| COVID_lost_job | -0.131 | 0.137 | -0.959 | 0.337 |
| scenario_type | -0.170 | 0.105 | -1.615 | 0.106 |
| COVID_gen_harm:scenario_type | 0.276 | 0.116 | 2.383 | 0.017 |
| COVID_pers_concern:scenario_type | -0.006 | 0.117 | -0.052 | 0.959 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod4, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)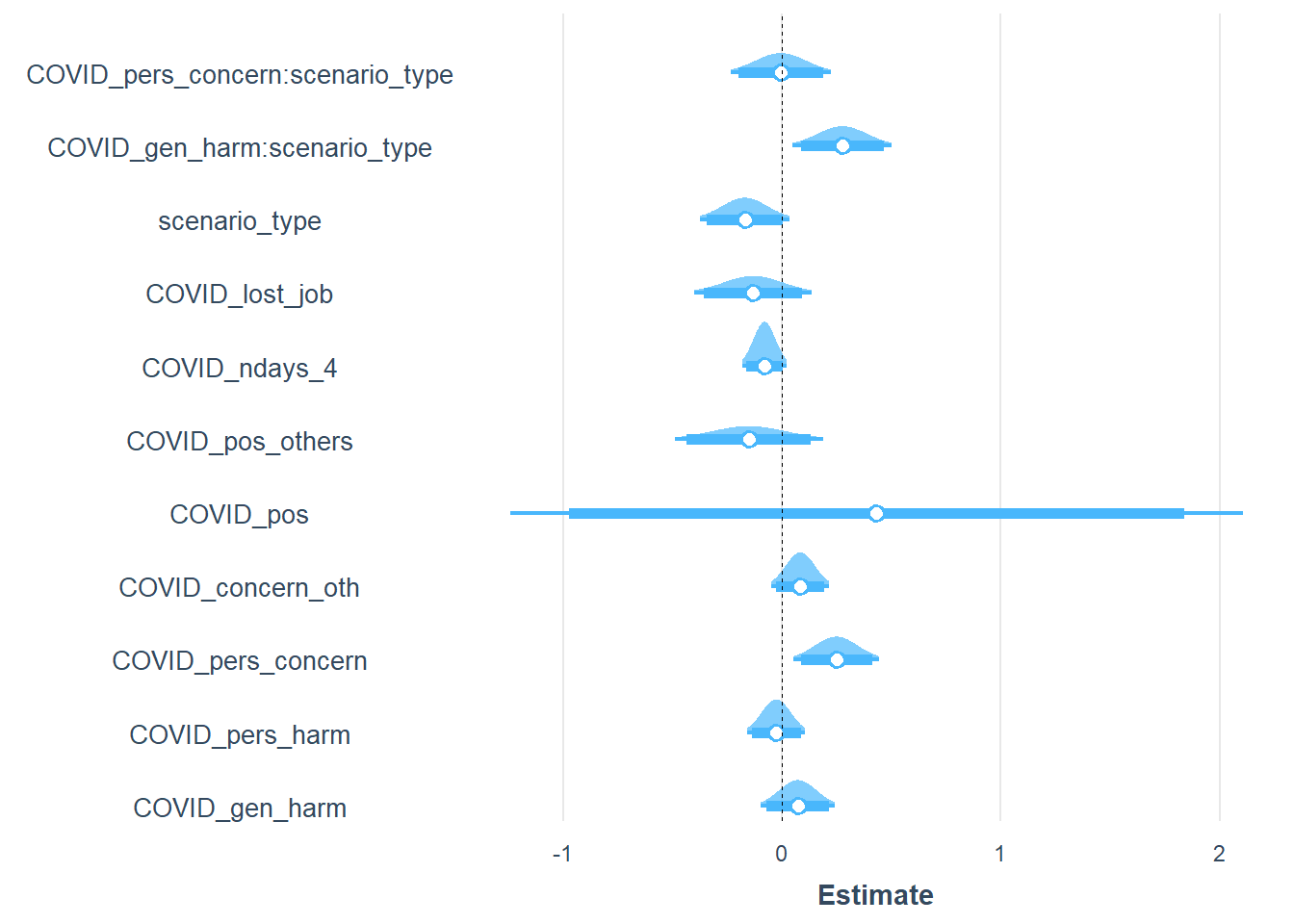
mod5 <- glm(accept2 ~ COVID_gen_harm + COVID_pers_harm + COVID_pers_concern + COVID_concern_oth + COVID_pos + COVID_pos_others + COVID_ndays_4 + COVID_lost_job + scenario_type + scenario_type:COVID_gen_harm + scenario_type:COVID_pers_concern, data = covfin, family = binomial)
summ(mod5,digits=3)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(11) | 84.211 |
| Pseudo-R² (Cragg-Uhler) | 0.064 |
| Pseudo-R² (McFadden) | 0.037 |
| AIC | 2220.372 |
| BIC | 2286.218 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -0.316 | 0.344 | -0.920 | 0.358 |
| COVID_gen_harm | 0.078 | 0.092 | 0.852 | 0.394 |
| COVID_pers_harm | -0.030 | 0.065 | -0.461 | 0.645 |
| COVID_pers_concern | 0.228 | 0.091 | 2.500 | 0.012 |
| COVID_concern_oth | 0.080 | 0.070 | 1.145 | 0.252 |
| COVID_pos | 0.458 | 0.854 | 0.536 | 0.592 |
| COVID_pos_others | -0.069 | 0.172 | -0.401 | 0.689 |
| COVID_ndays_4 | -0.012 | 0.008 | -1.434 | 0.152 |
| COVID_lost_job | -0.219 | 0.134 | -1.634 | 0.102 |
| scenario_typesevere | -1.331 | 0.445 | -2.990 | 0.003 |
| COVID_gen_harm:scenario_typesevere | 0.245 | 0.123 | 1.987 | 0.047 |
| COVID_pers_concern:scenario_typesevere | 0.066 | 0.108 | 0.614 | 0.539 |
| Standard errors: MLE |
summ(mod5,digits=3,scale=TRUE)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(11) | 84.211 |
| Pseudo-R² (Cragg-Uhler) | 0.064 |
| Pseudo-R² (McFadden) | 0.037 |
| AIC | 2220.372 |
| BIC | 2286.218 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 0.859 | 0.080 | 10.679 | 0.000 |
| COVID_gen_harm | 0.073 | 0.085 | 0.852 | 0.394 |
| COVID_pers_harm | -0.031 | 0.067 | -0.461 | 0.645 |
| COVID_pers_concern | 0.245 | 0.098 | 2.500 | 0.012 |
| COVID_concern_oth | 0.076 | 0.066 | 1.145 | 0.252 |
| COVID_pos | 0.458 | 0.854 | 0.536 | 0.592 |
| COVID_pos_others | -0.069 | 0.172 | -0.401 | 0.689 |
| COVID_ndays_4 | -0.073 | 0.051 | -1.434 | 0.152 |
| COVID_lost_job | -0.219 | 0.134 | -1.634 | 0.102 |
| scenario_type | -0.212 | 0.104 | -2.049 | 0.040 |
| COVID_gen_harm:scenario_type | 0.227 | 0.114 | 1.987 | 0.047 |
| COVID_pers_concern:scenario_type | 0.071 | 0.115 | 0.614 | 0.539 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod5, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)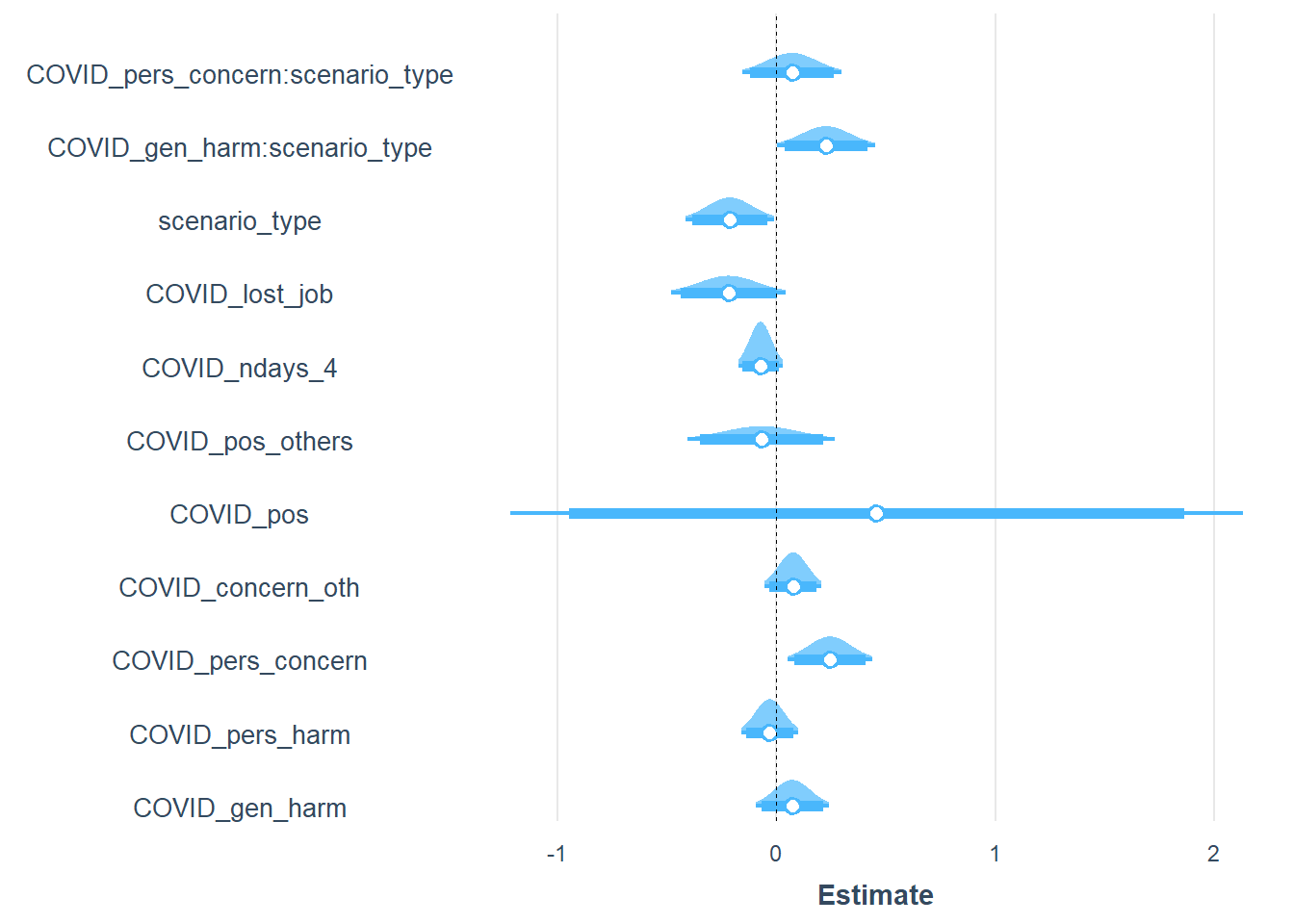
###############################################################################################################Perception of general severity interacts with type of scenario: People are even more likely to accept the severe scenario if people perceive higher general severity of COVID. This is true on both occasions.
6.2.3 Full model for acceptance
The final model (for now) combines all predictors including Worldview composite.
mod6 <- glm(accept1 ~ COVID_gen_harm + COVID_pers_harm + COVID_pers_concern + COVID_concern_oth + COVID_pos + COVID_pos_others +
COVID_ndays_4 + COVID_lost_job + scenario_type + scenario_type:COVID_gen_harm + scenario_type:COVID_pers_concern +
decline_participate + proportionality + sensitivity + risk_of_harm + trust_intentions + trust_respect_priv +
Worldview, data = covfin, family = binomial)
summ(mod6,digits=3)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(18) | 772.189 |
| Pseudo-R² (Cragg-Uhler) | 0.492 |
| Pseudo-R² (McFadden) | 0.346 |
| AIC | 1495.826 |
| BIC | 1600.082 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -2.613 | 0.629 | -4.157 | 0.000 |
| COVID_gen_harm | 0.090 | 0.116 | 0.775 | 0.439 |
| COVID_pers_harm | -0.008 | 0.083 | -0.101 | 0.919 |
| COVID_pers_concern | 0.111 | 0.119 | 0.927 | 0.354 |
| COVID_concern_oth | 0.207 | 0.093 | 2.219 | 0.026 |
| COVID_pos | 0.211 | 0.986 | 0.214 | 0.830 |
| COVID_pos_others | -0.254 | 0.215 | -1.183 | 0.237 |
| COVID_ndays_4 | -0.005 | 0.010 | -0.537 | 0.591 |
| COVID_lost_job | 0.265 | 0.171 | 1.551 | 0.121 |
| scenario_typesevere | -0.831 | 0.634 | -1.311 | 0.190 |
| decline_participate | -0.030 | 0.064 | -0.469 | 0.639 |
| proportionality | 0.326 | 0.051 | 6.401 | 0.000 |
| sensitivity | -0.093 | 0.058 | -1.592 | 0.111 |
| risk_of_harm | -0.198 | 0.051 | -3.876 | 0.000 |
| trust_intentions | 0.448 | 0.073 | 6.114 | 0.000 |
| trust_respect_priv | 0.380 | 0.074 | 5.163 | 0.000 |
| Worldview | -0.151 | 0.067 | -2.263 | 0.024 |
| COVID_gen_harm:scenario_typesevere | 0.307 | 0.158 | 1.940 | 0.052 |
| COVID_pers_concern:scenario_typesevere | 0.007 | 0.138 | 0.050 | 0.960 |
| Standard errors: MLE |
summ(mod6,digits=3,scale=TRUE)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept1 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(18) | 772.189 |
| Pseudo-R² (Cragg-Uhler) | 0.492 |
| Pseudo-R² (McFadden) | 0.346 |
| AIC | 1495.826 |
| BIC | 1600.082 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 1.108 | 0.164 | 6.760 | 0.000 |
| COVID_gen_harm | 0.083 | 0.108 | 0.775 | 0.439 |
| COVID_pers_harm | -0.009 | 0.085 | -0.101 | 0.919 |
| COVID_pers_concern | 0.119 | 0.128 | 0.927 | 0.354 |
| COVID_concern_oth | 0.196 | 0.088 | 2.219 | 0.026 |
| COVID_pos | 0.211 | 0.986 | 0.214 | 0.830 |
| COVID_pos_others | -0.254 | 0.215 | -1.183 | 0.237 |
| COVID_ndays_4 | -0.033 | 0.062 | -0.537 | 0.591 |
| COVID_lost_job | 0.265 | 0.171 | 1.551 | 0.121 |
| scenario_type | 0.320 | 0.276 | 1.158 | 0.247 |
| decline_participate | -0.066 | 0.140 | -0.469 | 0.639 |
| proportionality | 0.477 | 0.074 | 6.401 | 0.000 |
| sensitivity | -0.124 | 0.078 | -1.592 | 0.111 |
| risk_of_harm | -0.308 | 0.080 | -3.876 | 0.000 |
| trust_intentions | 0.754 | 0.123 | 6.114 | 0.000 |
| trust_respect_priv | 0.615 | 0.119 | 5.163 | 0.000 |
| Worldview | -0.152 | 0.067 | -2.263 | 0.024 |
| COVID_gen_harm:scenario_type | 0.285 | 0.147 | 1.940 | 0.052 |
| COVID_pers_concern:scenario_type | 0.008 | 0.149 | 0.050 | 0.960 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod6, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)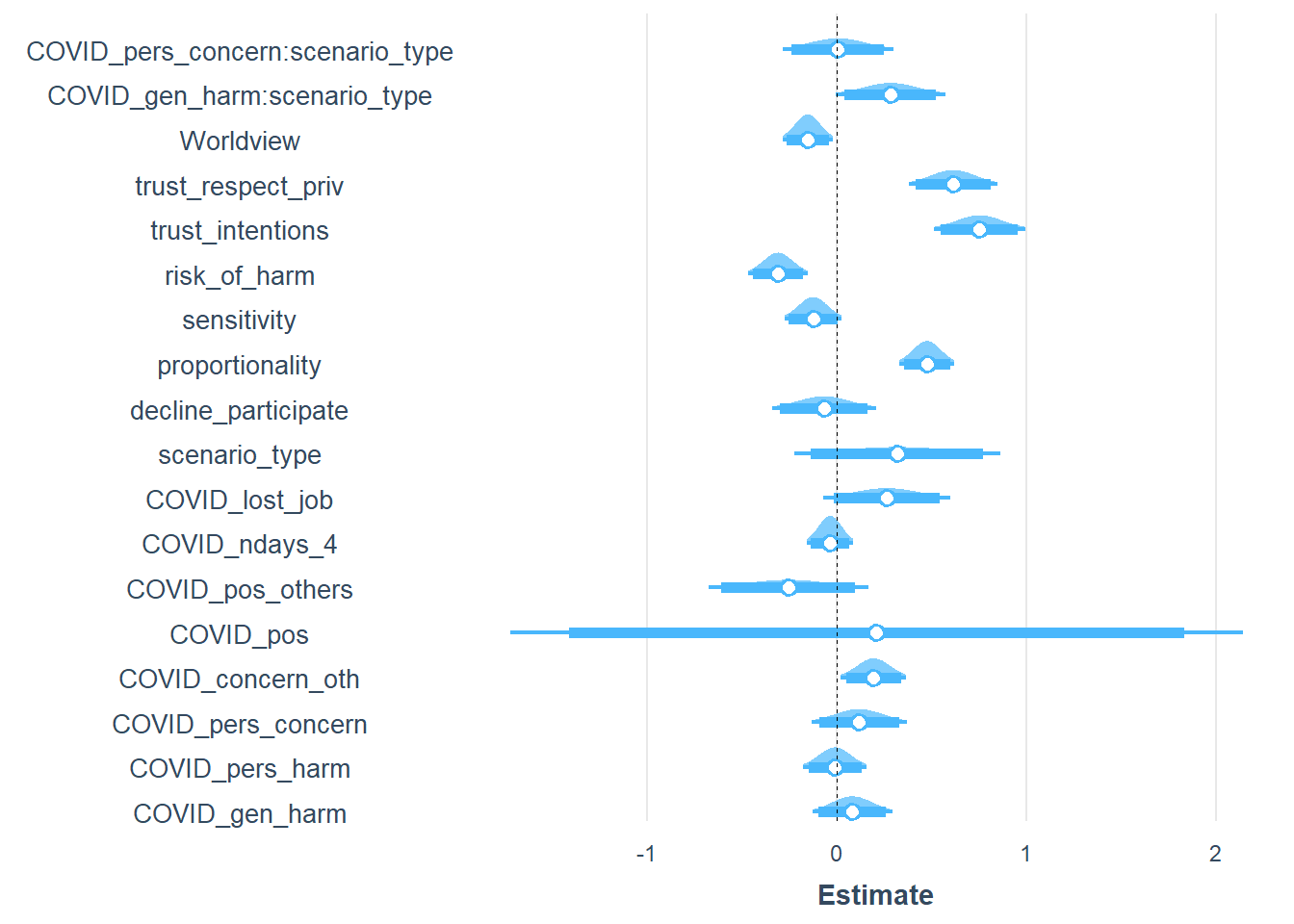
mod7 <- glm(accept2 ~ COVID_gen_harm + COVID_pers_harm + COVID_pers_concern + COVID_concern_oth + COVID_pos + COVID_pos_others +
COVID_ndays_4 + COVID_lost_job + scenario_type + scenario_type:COVID_gen_harm + scenario_type:COVID_pers_concern +
decline_participate + proportionality + sensitivity + risk_of_harm + trust_intentions + trust_respect_priv +
Worldview, data = covfin, family = binomial)
summ(mod7,digits=3)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(18) | 828.013 |
| Pseudo-R² (Cragg-Uhler) | 0.515 |
| Pseudo-R² (McFadden) | 0.363 |
| AIC | 1490.570 |
| BIC | 1594.826 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | -2.787 | 0.631 | -4.416 | 0.000 |
| COVID_gen_harm | 0.092 | 0.117 | 0.785 | 0.433 |
| COVID_pers_harm | -0.024 | 0.083 | -0.293 | 0.770 |
| COVID_pers_concern | 0.117 | 0.120 | 0.976 | 0.329 |
| COVID_concern_oth | 0.191 | 0.094 | 2.035 | 0.042 |
| COVID_pos | 0.283 | 0.989 | 0.286 | 0.775 |
| COVID_pos_others | -0.128 | 0.216 | -0.590 | 0.555 |
| COVID_ndays_4 | -0.003 | 0.010 | -0.286 | 0.775 |
| COVID_lost_job | 0.147 | 0.170 | 0.862 | 0.389 |
| scenario_typesevere | -1.006 | 0.640 | -1.573 | 0.116 |
| decline_participate | -0.032 | 0.064 | -0.505 | 0.614 |
| proportionality | 0.304 | 0.051 | 5.905 | 0.000 |
| sensitivity | -0.047 | 0.058 | -0.817 | 0.414 |
| risk_of_harm | -0.236 | 0.051 | -4.589 | 0.000 |
| trust_intentions | 0.496 | 0.073 | 6.835 | 0.000 |
| trust_respect_priv | 0.375 | 0.073 | 5.155 | 0.000 |
| Worldview | -0.143 | 0.067 | -2.129 | 0.033 |
| COVID_gen_harm:scenario_typesevere | 0.233 | 0.159 | 1.465 | 0.143 |
| COVID_pers_concern:scenario_typesevere | 0.127 | 0.140 | 0.908 | 0.364 |
| Standard errors: MLE |
summ(mod7,digits=3,scale=TRUE)| Observations | 1785 (25 missing obs. deleted) |
| Dependent variable | accept2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(18) | 828.013 |
| Pseudo-R² (Cragg-Uhler) | 0.515 |
| Pseudo-R² (McFadden) | 0.363 |
| AIC | 1490.570 |
| BIC | 1594.826 |
| Est. | S.E. | z val. | p | |
|---|---|---|---|---|
| (Intercept) | 1.025 | 0.164 | 6.243 | 0.000 |
| COVID_gen_harm | 0.085 | 0.108 | 0.785 | 0.433 |
| COVID_pers_harm | -0.025 | 0.086 | -0.293 | 0.770 |
| COVID_pers_concern | 0.126 | 0.129 | 0.976 | 0.329 |
| COVID_concern_oth | 0.181 | 0.089 | 2.035 | 0.042 |
| COVID_pos | 0.283 | 0.989 | 0.286 | 0.775 |
| COVID_pos_others | -0.128 | 0.216 | -0.590 | 0.555 |
| COVID_ndays_4 | -0.018 | 0.063 | -0.286 | 0.775 |
| COVID_lost_job | 0.147 | 0.170 | 0.862 | 0.389 |
| scenario_type | 0.270 | 0.277 | 0.974 | 0.330 |
| decline_participate | -0.071 | 0.141 | -0.505 | 0.614 |
| proportionality | 0.445 | 0.075 | 5.905 | 0.000 |
| sensitivity | -0.063 | 0.077 | -0.817 | 0.414 |
| risk_of_harm | -0.367 | 0.080 | -4.589 | 0.000 |
| trust_intentions | 0.836 | 0.122 | 6.835 | 0.000 |
| trust_respect_priv | 0.607 | 0.118 | 5.155 | 0.000 |
| Worldview | -0.144 | 0.068 | -2.129 | 0.033 |
| COVID_gen_harm:scenario_type | 0.216 | 0.147 | 1.465 | 0.143 |
| COVID_pers_concern:scenario_type | 0.136 | 0.150 | 0.908 | 0.364 |
| Standard errors: MLE; Continuous predictors are mean-centered and scaled by 1 s.d. |
plot_summs(mod7, scale = TRUE, plot.distributions = TRUE, inner_ci_level = .9)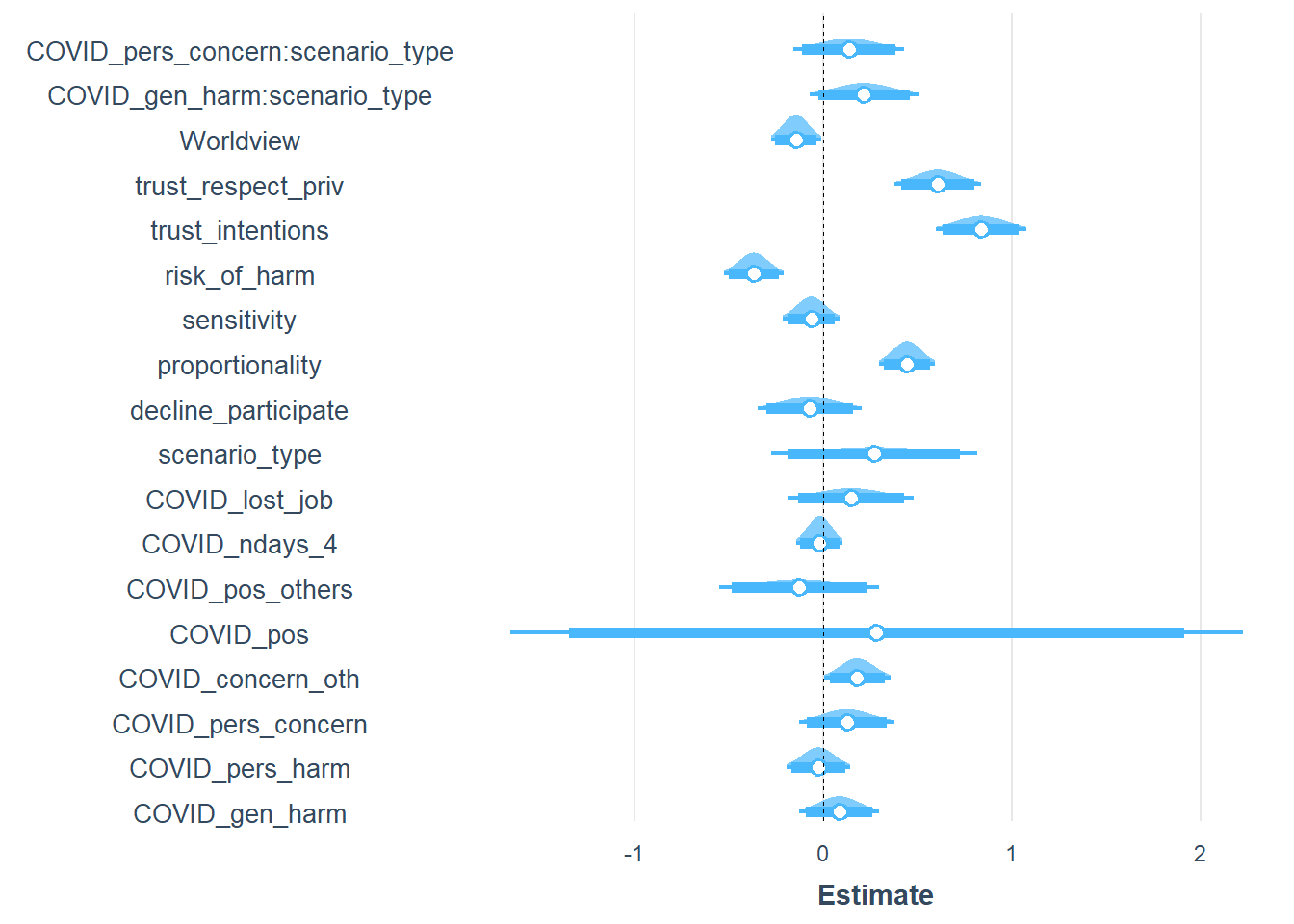
R version 3.6.3 (2020-02-29)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19042)
Matrix products: default
locale:
[1] LC_COLLATE=English_United Kingdom.1252
[2] LC_CTYPE=English_United Kingdom.1252
[3] LC_MONETARY=English_United Kingdom.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United Kingdom.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] broom.mixed_0.2.4 kableExtra_1.2.1 jtools_2.0.3 expss_0.10.2
[5] vioplot_0.3.4 zoo_1.8-7 sm_2.2-5.6 readxl_1.3.1
[9] summarytools_0.9.6 scales_1.1.0 psych_1.9.12.31 reshape2_1.4.4
[13] Hmisc_4.4-0 Formula_1.2-3 survival_3.2-3 gridExtra_2.3
[17] lme4_1.1-21 Matrix_1.2-18 forcats_0.5.0 stringr_1.4.0
[21] dplyr_0.8.5 purrr_0.3.4 readr_1.3.1 tidyr_1.0.2
[25] tibble_3.0.1 ggplot2_3.3.0 tidyverse_1.3.0 stargazer_5.2.2
[29] hexbin_1.28.1 lattice_0.20-41 knitr_1.30 workflowr_1.6.1
loaded via a namespace (and not attached):
[1] minqa_1.2.4 colorspace_1.4-1 pryr_0.1.4
[4] ellipsis_0.3.0 rprojroot_1.3-2 ggstance_0.3.4
[7] htmlTable_1.13.3 base64enc_0.1-3 fs_1.4.1
[10] rstudioapi_0.11 farver_2.0.3 fansi_0.4.1
[13] lubridate_1.7.8 xml2_1.3.2 codetools_0.2-16
[16] splines_3.6.3 mnormt_1.5-6 jsonlite_1.6.1
[19] nloptr_1.2.2.1 pbkrtest_0.4-8.6 broom_0.5.5
[22] cluster_2.1.0 dbplyr_1.4.2 png_0.1-7
[25] compiler_3.6.3 httr_1.4.1 backports_1.1.6
[28] assertthat_0.2.1 cli_2.0.2 later_1.0.0
[31] acepack_1.4.1 htmltools_0.4.0 tools_3.6.3
[34] lmerTest_3.1-2 coda_0.19-3 gtable_0.3.0
[37] glue_1.4.1 Rcpp_1.0.4.6 cellranger_1.1.0
[40] vctrs_0.2.4 nlme_3.1-145 xfun_0.20
[43] rvest_0.3.5 lifecycle_0.2.0 MASS_7.3-51.5
[46] hms_0.5.3 promises_1.1.0 parallel_3.6.3
[49] TMB_1.7.16 RColorBrewer_1.1-2 yaml_2.2.1
[52] pander_0.6.3 rpart_4.1-15 latticeExtra_0.6-29
[55] stringi_1.4.6 checkmate_2.0.0 boot_1.3-24
[58] rlang_0.4.6 pkgconfig_2.0.3 matrixStats_0.56.0
[61] evaluate_0.14 labeling_0.3 rapportools_1.0
[64] htmlwidgets_1.5.1 tidyselect_1.0.0 plyr_1.8.6
[67] magrittr_1.5 R6_2.4.1 magick_2.3
[70] generics_0.0.2 DBI_1.1.0 mgcv_1.8-31
[73] pillar_1.4.3 haven_2.2.0 whisker_0.4
[76] foreign_0.8-76 withr_2.2.0 nnet_7.3-13
[79] modelr_0.1.6 crayon_1.3.4 rmarkdown_2.6
[82] jpeg_0.1-8.1 grid_3.6.3 data.table_1.12.8
[85] git2r_0.26.1 webshot_0.5.2 reprex_0.3.0
[88] digest_0.6.25 numDeriv_2016.8-1.1 httpuv_1.5.2
[91] munsell_0.5.0 viridisLite_0.3.0 tcltk_3.6.3